구글이 밝힌 AI 에이전트 스케일링의 진실: 에이전트가 많을수록 성능은 떨어질 수 있다
최근 AI 엔지니어링 씬에서 가장 뜨거운 화두는 단연 Agentic Workflow 입니다. “LLM 하나로는 부족하다, 여러 에이전트를 묶어서 협업시켜야 한다”는 것이 정설처럼 받아들여지고 있죠. 실제로 “More Agents Is All You Need” 같은 논문들이 나오면서, 마치 에이전트 숫자를 늘리는 것이 성능 향상의 치트키인 것처럼 여겨지기도 했습니다.
하지만 현업에서 에이전트 시스템을 프로덕션에 태워본 분들은 아실 겁니다. 에이전트가 많아질수록 시스템은 복잡해지고, 디버깅은 지옥이 되며, 비용은 기하급수적으로 늘어난다는 것을요. 때마침 구글 리서치(Google Research)에서 이 ‘에이전트 만능설’에 제동을 거는 흥미로운 연구 결과를 내놓았습니다. 오늘은 이 리포트와 이에 대한 Hacker News의 반응을 엔지니어링 관점에서 씹어보고자 합니다.
”무조건 에이전트 추가”는 틀렸다
구글의 이번 연구 Towards a Science of Scaling Agent Systems는 180개의 에이전트 구성을 테스트하여 정량적인 스케일링 원칙을 도출했습니다. 결론부터 말하자면, 멀티 에이전트 시스템은 만병통치약이 아닙니다.
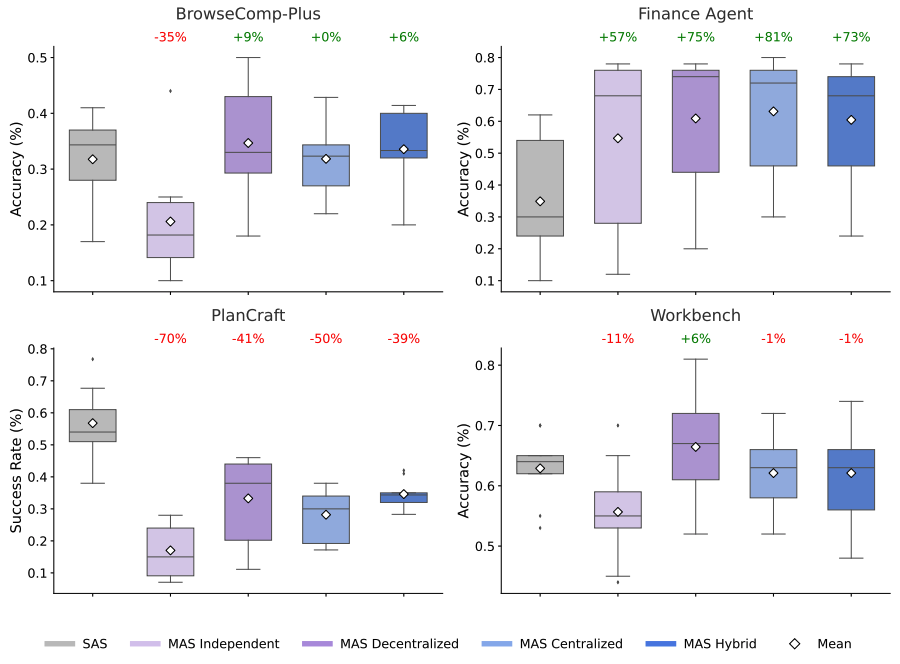
위 그래프가 핵심을 보여줍니다. 재무 분석(Finance-Agent)처럼 병렬 처리가 가능한 작업에서는 멀티 에이전트가 단일 에이전트보다 80% 이상 성능이 좋았습니다. 하지만 PlanCraft 같은 순차적(Sequential) 추론 이 필요한 작업에서는 오히려 성능이 39~70%까지 하락 했습니다.
이건 우리가 분산 시스템(Distributed Systems)을 설계할 때 겪는 문제와 정확히 일치합니다. 의존성이 강한 작업들을 억지로 마이크로서비스로 쪼개놨을 때, 네트워크 오버헤드와 데이터 정합성 문제로 전체 시스템 성능이 떨어지는 것과 같은 이치입니다.
아키텍처별 승자와 패자
연구팀은 다섯 가지 아키텍처를 비교했습니다:
- Single-Agent (SAS): 혼자 다 함.
- Independent: 서로 대화 없이 각자 일함.
- Centralized: 오케스트레이터(Hub)가 지시하고 취합함.
- Decentralized: 에이전트끼리 서로 소통함 (Mesh).
- Hybrid: 위 두 가지를 섞음.
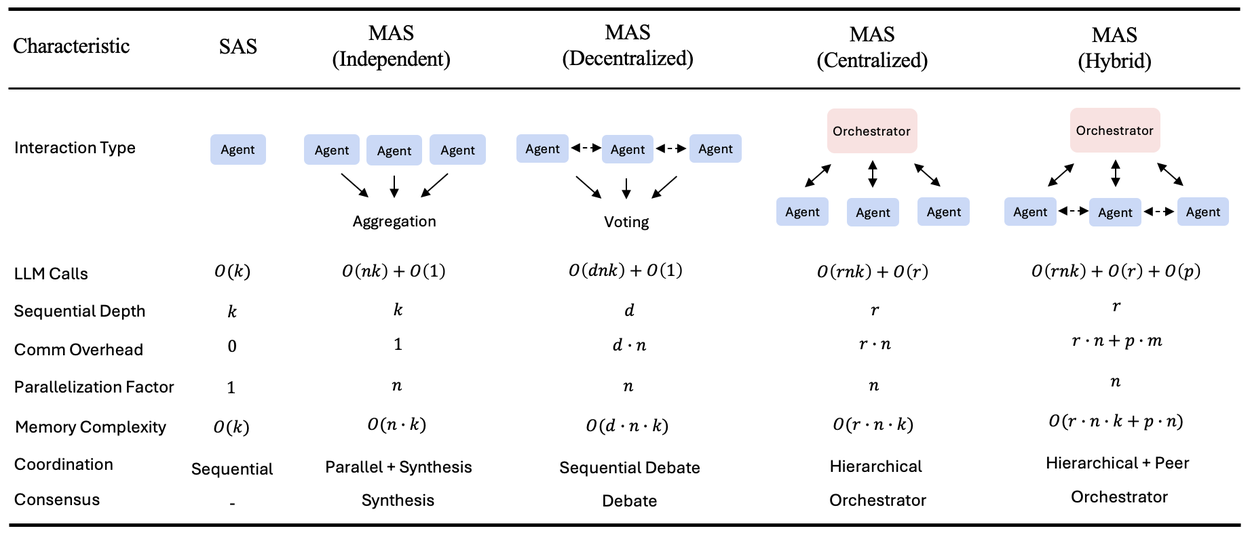
1. 병렬 작업의 승자: Centralized
서로 다른 데이터를 동시에 분석해야 하는 작업에서는 중앙 집중형 오케스트레이터가 압도적이었습니다. 복잡한 문제를 하위 작업(Sub-tasks)으로 쪼개서 뿌려주는 방식이 효과적이라는 뜻입니다.
2. 순차 작업의 패배자: 모든 멀티 에이전트
앞선 단계의 결과가 다음 단계의 입력이 되어야 하는 경우, 에이전트 간의 커뮤니케이션 비용이 추론의 맥락(Context)을 파편화시킵니다. “Cognitive Budget”을 작업 자체가 아니라 서로 대화하는 데 낭비하게 되는 셈이죠.
3. 도구(Tool) 사용의 병목
사용 가능한 도구가 많아질수록(예: 16개 이상의 툴을 가진 코딩 에이전트), 에이전트 간 조율 비용(Coordination Tax)이 급격히 증가합니다. 툴이 많으면 그냥 똑똑한 놈 하나(SAS)가 낫다는 결과가 나왔습니다.
공포의 에러 전파 (Error Amplification)
CTO로서 가장 섬뜩했던 데이터는 바로 ‘신뢰성’ 부분입니다.
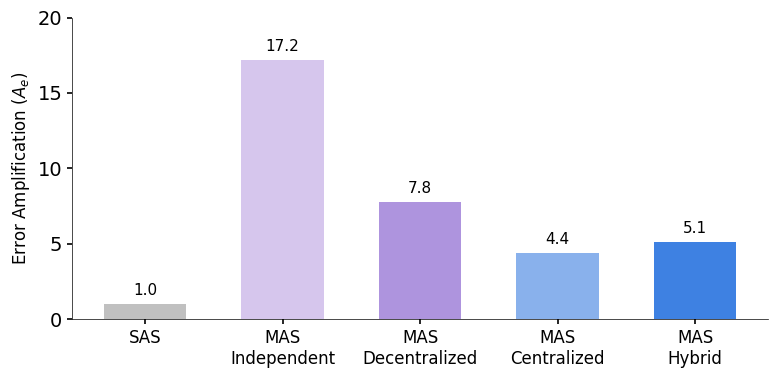
- Independent Multi-Agent: 에러가 발생하면 서로 검증하는 메커니즘이 없어 에러가 17.2배 증폭됩니다.
- Centralized: 오케스트레이터가 “Validation Bottleneck” 역할을 하여 에러 전파를 4.4배 로 억제합니다.
프로덕션 환경에서 ‘Independent’ 방식의 에이전트 스웜(Swarm)을 쓴다는 건, 사실상 디버깅을 포기하겠다는 선언과 다를 바 없어 보입니다. 누군가는 반드시 결과물을 검증(Validation)해야 합니다.
Hacker News의 반응과 엔지니어링 인사이트
Hacker News의 토론에서도 날카로운 지적들이 쏟아졌습니다.
”소프트웨어 공학의 기본으로 돌아가라”
한 유저는 이 결과가 “높은 응집도, 낮은 결합도(High Cohesion, Loosely Coupled)” 원칙과 정확히 일치한다고 지적했습니다. AI라고 해서 마법은 아닙니다. 컴포넌트 간의 통신이 많아지면 복잡도는 증가합니다. 에이전트 설계를 할 때도 이 고전적인 원칙을 따라야 합니다.
”오케스트레이터보다는 평가자(Evaluator)가 핵심”
또 다른 유저는 자신의 경험을 공유하며, 중앙 오케스트레이터보다 더 중요한 건 각 액션의 결과를 검증하는 특화된 평가자(Specialized Evaluator) 라고 말했습니다. Claude가 코드를 짜고, GPT-4o가 리뷰하는 식의 ‘이종 모델 간 검증’이 단일 모델의 컨텍스트 오염을 막는 데 효과적이라는 의견입니다. 저도 이 부분에 크게 공감합니다. LLM은 자신의 실수를 스스로 발견하기 어렵기 때문이죠.
”구글의 제품력에 대한 회의”
물론 구글에 대한 비판도 빠지지 않았습니다. “논문은 그럴듯하지만, 실제 구글의 AI 제품(Gemini 등)은 사용자 경험이 엉망이다”라는 의견이 많았습니다. 특히 에러 데이터에 대한 심층적인 분석이 부족하다는 ‘Shallow paper’라는 비판도 있었는데, 이는 학술적 엄밀함보다는 트렌드에 맞춘 리포트 성격이 강해서일 겁니다.
결론: 은탄환은 없다
이 리포트가 주는 교훈은 명확합니다. “무지성 멀티 에이전트 도입을 멈춰라” 입니다.
여러분이 만들고 있는 시스템이 병렬 처리가 가능한 독립적인 작업 들로 구성되어 있다면, 중앙 집중형(Centralized) 멀티 에이전트 구조를 도입하세요. 하지만 긴 호흡의 논리적 추론이 필요한 순차적 작업 이라면, 억지로 에이전트를 쪼개지 말고 성능 좋은 단일 모델(SAS)에 튼튼한 프롬프트 엔지니어링과 툴을 쥐여주는 것이 낫습니다.
우리는 지금 AI의 ‘연금술’ 시대를 지나 ‘공학’의 시대로 넘어가고 있습니다. 단순히 “에이전트를 10개 붙였더니 잘되더라”가 아니라, 작업의 특성(Task Properties)에 맞춰 아키텍처를 설계하는 Engineering Decision 이 필요한 시점입니다.