Triton Compiler Internals: 왜 우리는 여전히 Bespoke Layout을 버리지 못하는가?
최근 Triton 컴파일러의 내부 구조를 파헤치다 보면, 흥미로운 긴장 관계를 목격하게 됩니다. 바로 Linear Layout(선형 레이아웃) 이라는 우아하고 일반화된 이론과, Bespoke Layout(맞춤형 레이아웃) 이라고 불리는 투박하지만 실용적인 현실 사이의 줄다리기입니다.
엔지니어로서 우리는 항상 ‘일반화(Generalization)‘를 꿈꿉니다. 모든 하드웨어 특성을 아우르는 단 하나의 완벽한 추상화 계층을 만들고 싶어 하죠. 하지만 현업에서 15년 넘게 굴러본 경험으로 말하자면, 하드웨어는 그렇게 호락호락하지 않습니다. 특히 GPU처럼 극한의 성능을 짜내야 하는 환경에서는 더욱 그렇습니다.
오늘은 Triton의 Bespoke Layout이 왜 여전히 중요한지, 그리고 이것이 실제 하드웨어의 메모리 계층 구조와 어떻게 맞물려 돌아가는지 딥다이브 해보겠습니다.
1. Bespoke vs Linear: 이상과 현실의 괴리
이전 글들에서 소개된 Linear Layout은 수학적으로 매우 아름답습니다. 모듈러 연산과 XOR 등을 이용해 데이터의 위치를 수식으로 깔끔하게 정의하죠. 컴파일러 최적화 관점에서는 꿈의 도구입니다.
하지만 Blocked, Shared, MMA 같은 Bespoke Layout 들은 여전히 Triton의 핵심을 차지하고 있습니다. 왜일까요? 간단합니다. 직관적이고, 하드웨어 그 자체이기 때문입니다.
우리가 CUDA 커널을 짤 때를 생각해보세요. “스레드 하나가 요소 4개를 맡고, 워프는 32개 스레드로 구성되며…” 이런 식으로 사고합니다. Bespoke Layout은 바로 이 사고방식을 그대로 IR(Intermediate Representation)로 옮겨 놓은 것입니다. Linear Layout이 어셈블리라면, Bespoke Layout은 우리가 작성하는 C++ 코드나 마찬가지인 셈입니다.
물론, 이 두 세계를 연결하는 건 골치 아픈 문제입니다. 컴파일러 내부에서는 ttg.convert_layout이라는 연산이 이 둘 사이의 다리 역할을 합니다. 소스 레이아웃과 타겟 레이아웃의 조합(Combinatorial problem)을 해결해야 하는데, 이 과정이 복잡해질수록 최적화의 난이도는 기하급수적으로 올라갑니다.
2. Distributed Layouts: 레지스터와 SIMT의 세계
분산 레이아웃(Distributed Layout)은 각 하드웨어 유닛이 텐서의 어느 부분을 소유할지를 결정합니다. 여기서 가장 기본이 되는 것이 바로 Blocked Layout 입니다.
Blocked Layout과 Order의 함정
GPU는 기본적으로 SIMT(Single Instruction, Multiple Threads) 모델입니다. 메모리에서 데이터를 가져올 때, 워프(Warp) 내의 스레드들이 연속된 메모리 주소를 액세스해야 Coalescing 이 발생하여 성능 저하를 막을 수 있습니다.
Blocked Layout은 이를 위해 size_per_thread, threads_per_warp, warps_per_cta 같은 속성을 정의합니다. 여기서 재미있는 점은 order 속성입니다. 차원의 순서를 정의하는데, 이 순서 하나만 바뀌어도 워프 내 스레드 배치가 완전히 달라집니다.
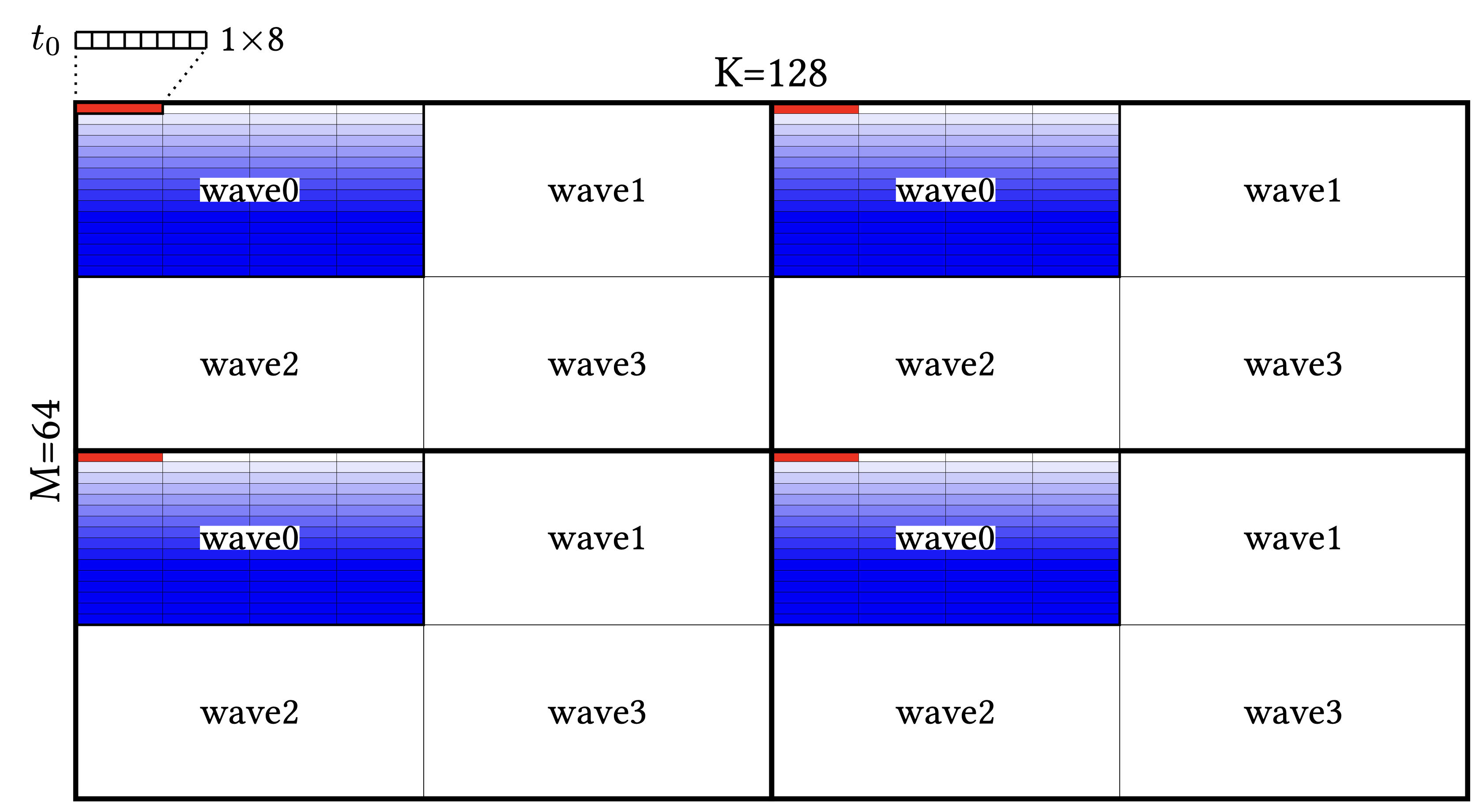
위 그림을 보면 64x128 텐서에 order=[1, 0]을 적용했을 때의 배치입니다. 만약 order를 바꾸면 워프의 배치 패턴이 완전히 뒤집힙니다. 솔직히 말해서, 이런 order 비트 하나에 성능이 널뛰기하는 구조는 개발자에게 꽤나 높은 인지 부하(Cognitive Burden)를 줍니다. 하지만 하드웨어의 물리적 특성을 맞추려면 어쩔 수 없는 선택이기도 하죠.
MMA Layouts: 벤더별 춘추전국시대
데이터를 레지스터로 가져왔다면, 이제 Tensor Core(또는 Matrix Core)에 먹여줘야 합니다. 여기서부터는 표준이 없습니다. NVIDIA의 MMA와 AMD의 MFMA는 데이터 소유 패턴이 완전히 다릅니다.
특히 AMD의 경우 instruction shape과 version에 따라 레이아웃이 결정되는데, 흥미로운 점은 Transposed bit 입니다. 예를 들어, tl.dot 연산을 체이닝(Chaining)할 때, 앞선 연산의 출력이 다음 연산의 입력으로 들어가는 경우가 많습니다. 이때 메모리 레이아웃이 맞지 않으면 불필요한 데이터 셔플링이 발생합니다. 이를 막기 위해 $C^T = B^T A^T$라는 수학적 트릭을 이용해 전치(Transpose)된 상태로 연산을 수행하도록 유도하는 최적화가 숨어있습니다.
3. Shared Layouts: Bank Conflict와의 전쟁
개인적으로 가장 흥미로운 부분은 Shared Memory(LDS) 처리 방식입니다. 여기서 NVIDIA와 AMD의 아키텍처 차이가 극명하게 드러납니다.
Swizzled Layout (NVIDIA 스타일)
전통적인 방식입니다. Shared Memory의 Bank Conflict를 피하기 위해 주소에 XOR 연산을 적용합니다(Swizzling). 이는 Linear Layout의 철학(XOR 기반)과도 잘 맞아떨어집니다. vec, perPhase, maxPhase 같은 파라미터로 스위즐링 패턴을 정의하여, 인접한 스레드들이 서로 다른 뱅크에 접근하도록 만듭니다.
Padded Layout (AMD 스타일)
하지만 AMD의 최신 아키텍처(CDNA4 등)에서는 상황이 다릅니다. GLOBAL_LOAD_LDS_* 같은 인스트럭션은 글로벌 메모리에서 Shared Memory로 데이터를 직접 씁니다. 레지스터를 거치지 않으므로 레지스터 압박(Register Pressure)을 줄여주는 훌륭한 기능이죠.
문제는 이 명령어가 워프 전체에 대해 단일 베이스 주소만을 사용한다는 점입니다. 즉, 우리가 원하는 대로 주소를 비트 단위로 꼬는(Swizzling) 것이 불가능하거나 매우 비효율적입니다.
그래서 등장한 것이 Padded Shared Layout 입니다. Bank Conflict를 피하기 위해 XOR 대신 물리적인 Padding(빈 공간) 을 삽입하는 방식입니다.
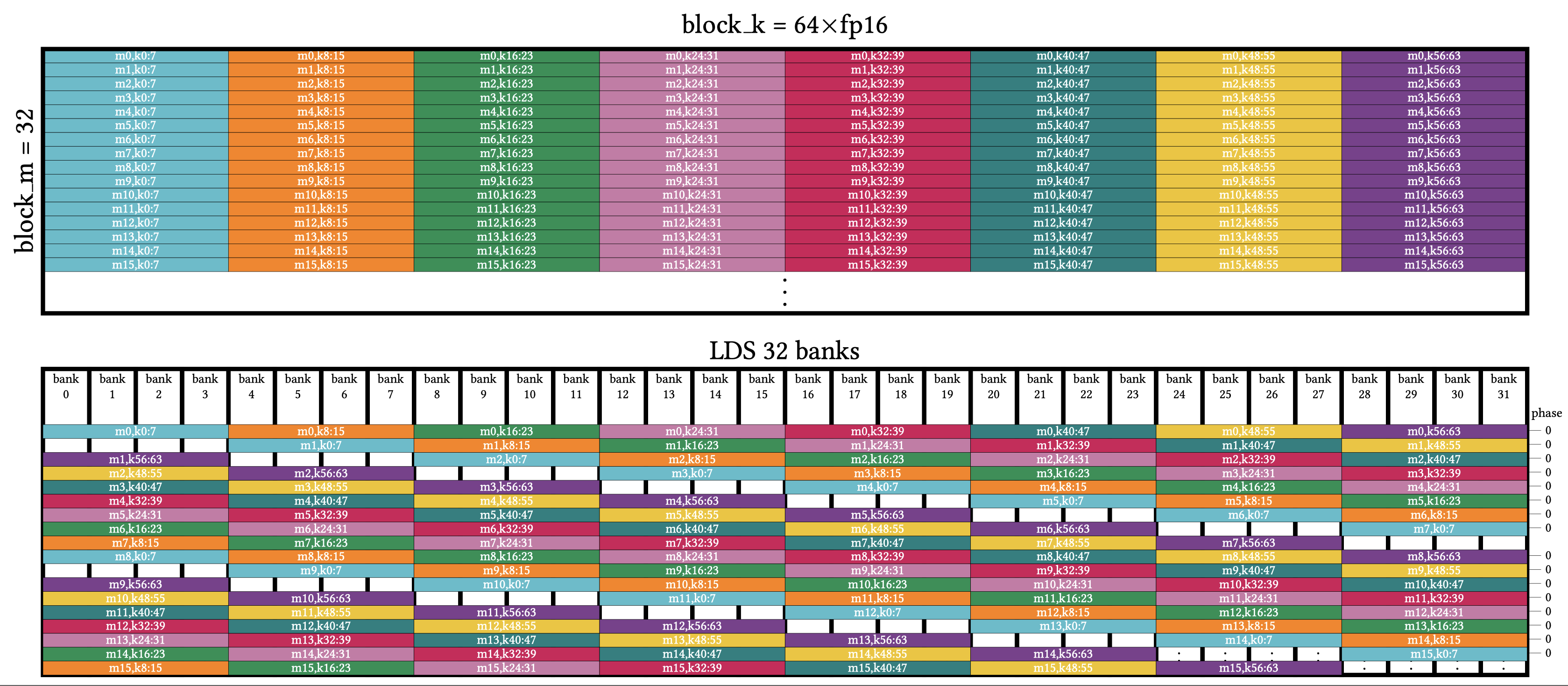
위 그림처럼 특정 간격마다 패딩을 넣어 데이터가 밀리게 만듭니다. 이렇게 하면 낭비되는 메모리 공간이 생기지만, 하드웨어의 제약 사항을 우회하여 고성능을 낼 수 있는 유일한 방법이기도 합니다. 이는 Linear Layout의 일반적인 법칙(덧셈이 아닌 XOR 기반)을 깨뜨리는 예외적인 케이스지만, “성능을 위해서라면 예외를 허용한다” 는 엔지니어링의 현실을 잘 보여줍니다.
4. 마치며: 추상화 뒤에 숨은 디테일
Triton이 매력적인 이유는 파이썬이라는 고수준 언어로 GPU 프로그래밍을 가능하게 하면서도, 내부적으로는 이런 Bespoke Layout을 통해 하드웨어의 밑바닥까지 제어할 수 있는 길을 열어두었기 때문입니다.
Linear Layout이 컴파일러 최적화의 미래라면, Bespoke Layout은 우리가 발 디디고 있는 현재의 하드웨어 그 자체입니다. 개발자로서 우리는 이 두 가지를 모두 이해해야 합니다. 특히 Gluon 같은 새로운 기능이 나오면서 개발자가 직접 레이아웃을 프로그래밍할 수 있게 된 지금, 이러한 내부 동작 원리를 아는 것은 단순한 지적 유희를 넘어 성능 최적화의 필수 조건이 되었습니다.
결국 모든 고수준 언어는 어셈블리로 변환됩니다. 하지만 그 변환 과정이 마법이 아니라, 치열한 고민과 하드웨어에 대한 타협의 산물이라는 점을 기억해야겠습니다.