63TiB의 체스 데이터와 대서양을 건넌 하드디스크: Lichess의 8-piece 테이블베이스 분석
최근 Lichess가 8-piece(기물 8개) 엔드게임 테이블베이스 의 일부를 공개했습니다. 데이터 크기만 무려 63TiB 입니다.
보통 이런 뉴스를 접하면 “와, 데이터 크네” 하고 넘어가기 쉽지만, 시니어 엔지니어의 관점에서 뜯어보면 이 프로젝트는 ‘무식하게 큰 데이터’를 다루는 실용적인 엔지니어링의 정수 를 보여줍니다. 특히, 인터넷이 아닌 ‘물리적 하드디스크’를 택배로 보내 데이터를 전송했다는 점이 제 향수를 자극하더군요.
오늘은 Lichess가 어떻게 이론적으로 불가능해 보이는 8-piece 체스 엔드게임을 ‘Op1’이라는 영리한 제약조건으로 풀어냈는지, 그리고 이 거대한 데이터를 서빙하기 위해 어떤 최적화 기법을 사용했는지 깊게 파고들어 보겠습니다.
1. 왜 8-piece는 ‘불가능’의 영역이었나?
먼저 배경 지식이 필요합니다. 체스 엔드게임 테이블베이스는 ‘해당 기물 조합으로 나올 수 있는 모든 경우의 수’를 미리 계산해 둔 DB입니다. 7-piece(기물 7개)까지는 이미 Syzygy 테이블베이스로 정복되었죠.
하지만 기물이 하나 늘어날 때마다 경우의 수는 기하급수적으로 폭발합니다.
- 7-piece: 약 4.2 x 10^14 포지션
- 8-piece: 약 3.8 x 10^16 포지션
단순 계산으로도 7-piece보다 약 100배 더 큽니다. 이걸 전부 저장하고 실시간으로 서빙하는 건 현재 하드웨어 비용상 비효율적입니다. 여기서 Lichess 팀과 수학자 Marc Bourzutschky는 엔지니어들이 가장 잘하는 짓(?)을 저지릅니다. 바로 “문제를 재정의하는 것” 입니다.
2. Op1: 50%의 커버리지, 1.3%의 데이터
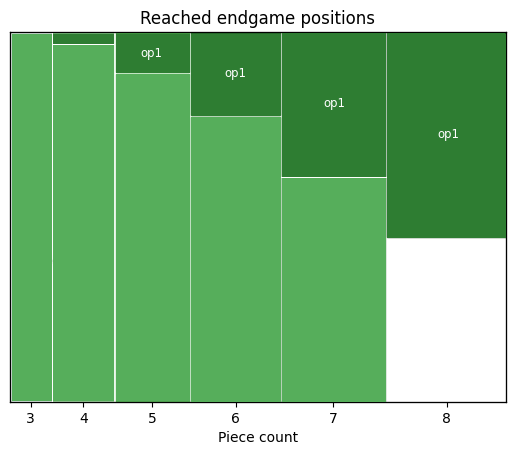
전체를 다 풀 수 없다면, 가장 빈번하게 발생하는 부분만 풀면 됩니다. 그게 바로 Op1(Opposing Pair 1) 입니다.
Op1은 “서로의 진로를 막고 있는 폰 쌍(Opposing Pair)이 적어도 하나 존재하는 포지션” 을 의미합니다. 예를 들어 백폰이 e4, 흑폰이 e5에 있어 서로 못 움직이는 상황이죠. 이 제약 조건이 엔지니어링적으로 훌륭한 이유는 두 가지입니다.
- Closed Set (닫힌 집합): 서로 막힌 폰은 캡처가 발생하지 않는 한 승진(Promotion)할 수 없습니다. 즉, 폰이 승진해서 기물 수가 변하는 복잡한 경우의 수를 계산할 필요 없이, 캡처가 발생하면 이미 정복된 7-piece 테이블로 환원됩니다.
- 실용성: 놀랍게도 실제 게임에서 발생하는 8-piece 엔드게임의 약 50% 가 이 Op1 조건에 해당합니다.
결과적으로 전체 8-piece 경우의 수 중 단 1.3%의 용량(63TiB) 만으로 실전 상황의 절반 을 커버하는 가성비 최고의 솔루션을 만들어낸 겁니다. Pareto 법칙(80/20 법칙)의 체스 버전이라고 볼 수 있겠네요.
3. Sneakernet: 대역폭의 제왕은 여전히 ‘택배’
제가 이 글을 쓰게 된 결정적인 계기입니다. 2025년에도 대용량 데이터 전송의 왕은 여전히 Sneakernet 이었습니다.
미국에 있는 Marc와 유럽에 있는 Niklas(Lichess 개발자)는 가정용 인터넷을 쓰고 있었습니다. 63TiB를 인터넷으로 올린다? 몇 달이 걸릴지 모릅니다. 결국 그들은 하드디스크 3개를 박스에 담아 대서양을 건너게 했습니다.

“Never underestimate the bandwidth of a station wagon full of tapes hurtling down the highway.” — Andrew Tanenbaum
클라우드 시대에도 물리적 전송이 가장 빠른 해결책이라는 사실이 묘한 카타르시스를 줍니다. 최종 업로드는 지인들의 Fiber 인터넷을 빌려 500Mbit/s로 2주 동안 쏘아 올렸다고 합니다. 이런 ‘헝그리 정신’이 Lichess를 좋아하는 이유 중 하나입니다.
4. Rust와 Tail Latency 최적화
서빙 아키텍처도 흥미롭습니다. lila-tablebase는 Rust(Axum, Tokio)로 작성되었습니다. 63TiB 데이터는 당연히 RAM에 다 못 올리니 디스크 I/O가 병목이 될 수밖에 없습니다. 여기서 그들은 Throughput(처리량)보다는 Tail Latency(상위 99% 지연시간) 를 잡는 전략을 택했습니다.
병렬 Probing과 예측 실행
체스 엔진이 수를 분석할 때, 현재 포지션의 자식 노드(다음 수들)를 조회해야 합니다. Lichess는 이를 병렬로 처리하여 I/O 스케줄러가 더 효율적으로 디스크를 읽도록 유도했습니다.
특히 재미있는 건 “승패 예측(Guessing)” 로직입니다.
- 일반적으로 테이블베이스 조회는 승/무/패 값을 찾기 위해 인덱스를 조회합니다.
- 하지만 Op1 구조상, 한 번의 조회로 정확한 값을 모를 때가 있어 미러링 된 포지션(흑백 반전)까지 조회해야 할 수도 있습니다.
- Lichess는 통계적으로 “이쪽이 이기고 있을 것이다” 라고 가정하고 첫 번째 조회를 시도합니다. 예측이 맞으면 1번의 I/O로 끝납니다. 틀리면 그때 2번째 조회를 합니다.
- 무승부는 항상 2번 조회가 필요하지만, 승패가 갈리는 대부분의 경우 I/O를 절반으로 줄일 수 있습니다.
또한, 압축된 블록을 읽을 때 부분 읽기(Partial Read)를 시도하다가 다시 읽는 오버헤드를 피하기 위해, 아예 블록 전체를 한 번에 읽어서(Read Whole Block) 페이지 캐시(Page Cache) 효율을 극대화했습니다. 디스크 I/O 비용이 비싼 환경에서는 이런 ‘무식한’ 읽기가 오히려 레이턴시에 유리할 때가 많습니다.
5. 마치며: 완벽함보다는 ‘임팩트’
엔지니어로서 우리는 종종 “모든 엣지 케이스를 해결하기 전까진 릴리즈 하지 않겠다”는 완벽주의의 함정에 빠집니다. 만약 Lichess가 “완벽한 8-piece 테이블”을 고집했다면 우리는 아마 10년 뒤에나 이 기능을 봤을 겁니다.
하지만 그들은:
- Op1 이라는 실용적인 부분집합을 정의했고,
- 물리적 배송 이라는 원시적인 전송 방식을 택했으며,
- DTC(Depth to Conversion) 메트릭을 사용하여 사용자 경험(빠른 승리)에 집중했습니다.
이것이 바로 Engineering 입니다. 자원이 제한된 상황에서 문제를 정의하고, 트레이드오프를 계산하여 최적의 해를 내놓는 것.
63TiB의 데이터가 여러분의 브라우저에서 0.1초 만에 승리 수순을 알려줄 때, 그 뒤에 숨겨진 대서양을 건넌 하드디스크와 Rust 코드의 최적화를 한 번쯤 떠올려 보시길 바랍니다.
Reference: