Nvidia FP64의 15년 역사와 Blackwell Ultra가 깨뜨린 패턴
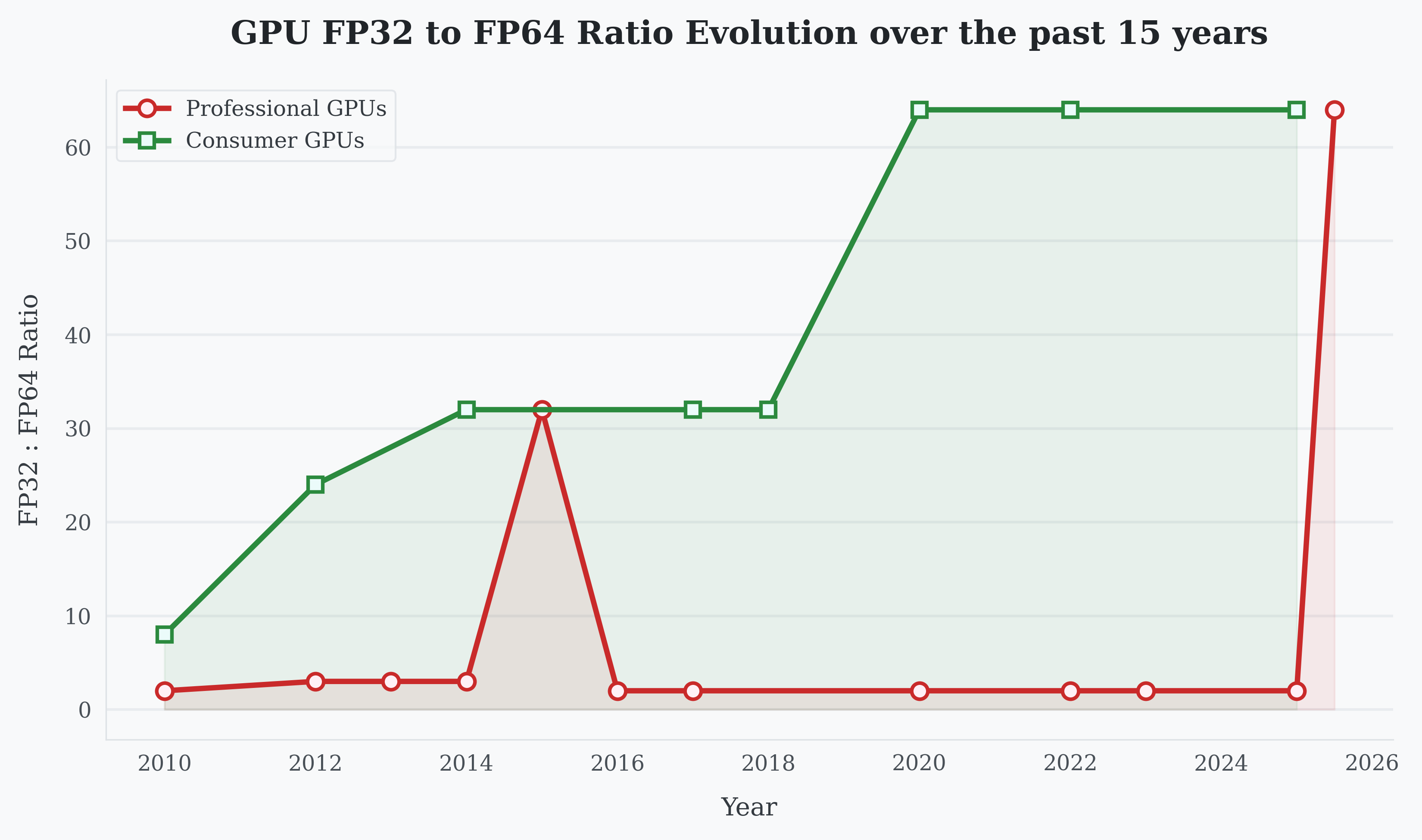
엔지니어로서 하드웨어 스펙 시트를 볼 때 가장 흥미로운 건 ‘무엇이 추가되었나’가 아니라 ‘무엇이 제거되었나’ 입니다. 최근 발표된 RTX 5090의 스펙을 보셨나요? FP32(단정밀도) 연산 성능은 무려 104.8 TFLOPS에 달합니다. 하지만 FP64(배정밀도) 연산을 시키면? 고작 1.64 TFLOPS가 나옵니다. 비율로 따지면 64:1입니다.
이건 기술적 한계가 아닙니다. 지난 15년 동안 Nvidia가 소비자용(GeForce)과 엔터프라이즈용(Tesla/Data Center) 시장을 나누기 위해 쌓아올린 거대한 장벽이었습니다. 그런데 최근 Blackwell Ultra 아키텍처를 기점으로 이 견고했던 논리가 무너지고 있습니다. 오늘은 그 기술적 배경과 시장의 변화를 엔지니어의 시각에서 파헤쳐 보겠습니다.
1. 15년간의 의도적인 성능 거세 (The Great Divide)
2010년 Fermi 아키텍처 시절을 기억하시는 분들이 계실지 모르겠습니다. 당시 GTX 480은 하드웨어적으로는 1:2의 FP64 비율을 지원했지만, 드라이버 레벨에서 1:8로 캡(Cap)이 씌워져 있었습니다. Nvidia는 처음에는 소프트웨어로 막았지만, 시간이 지날수록 아키텍처 레벨에서 물리적인 차별 을 두기 시작했습니다.
- Fermi (2010): 1:8
- Kepler (2012): 1:24
- Ampere (2020): 1:64
결과적으로 지난 15년 동안 소비자용 GPU의 FP32 성능이 77배 증가할 때, FP64 성능은 고작 9.6배 증가하는 데 그쳤습니다. 이는 명백한 Market Segmentation 전략입니다. 게임이나 렌더링 같은 소비자 Workload는 FP64가 필요 없지만, 유체 역학(CFD)이나 금융 모델링 같은 HPC 분야는 필수적이기 때문이죠.
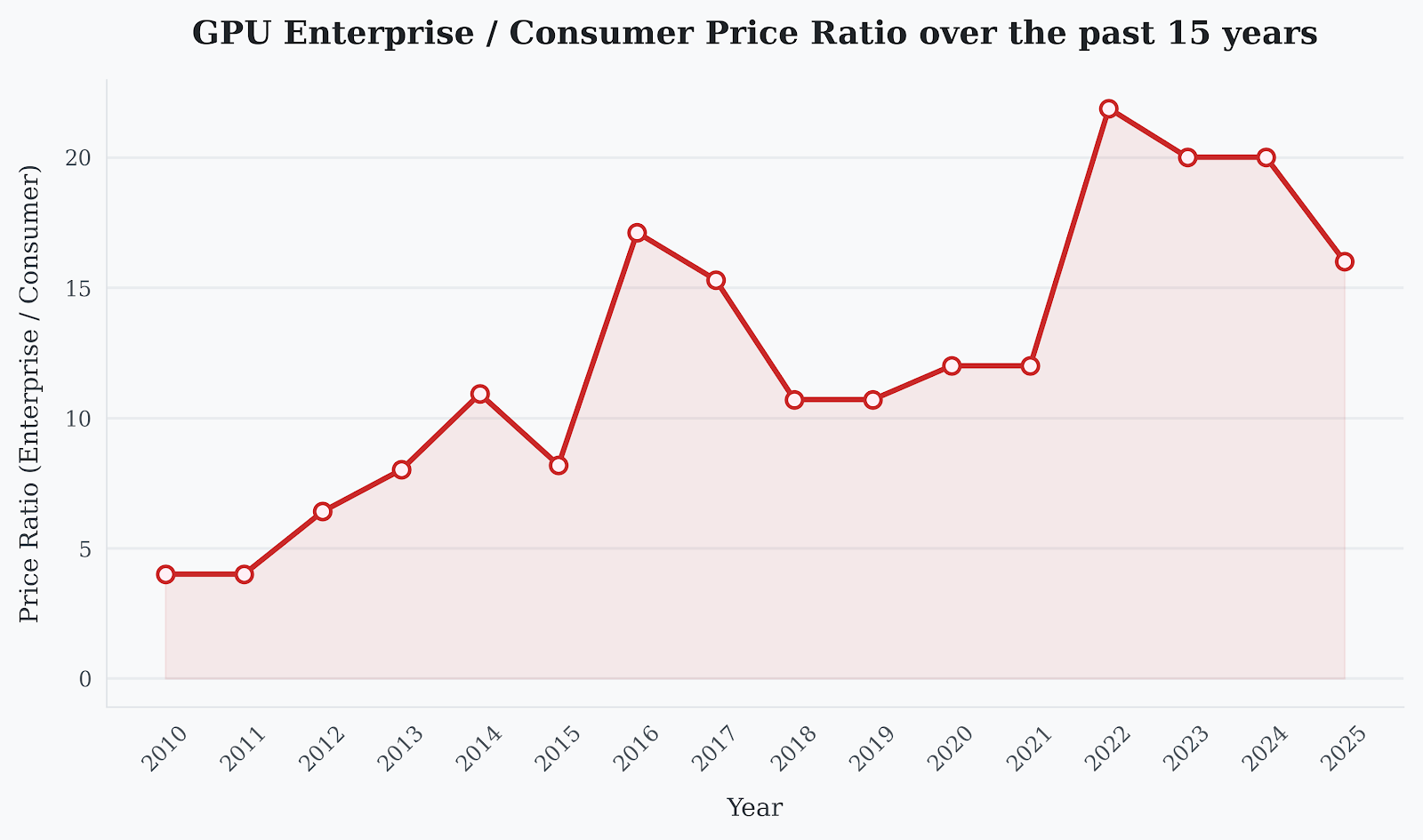
솔직히 엔지니어 입장에서 보면, 같은 실리콘 다이(Die)를 두고 이렇게까지 성능을 제한하는 게 얄밉기도 합니다. 하지만 비즈니스 관점에서는 천재적이었습니다. FP64라는 단 하나의 기능을 지렛대 삼아 엔터프라이즈 카드의 가격을 소비자용 대비 20배 이상으로 끌어올렸으니까요.
2. AI가 불러온 균열과 EULA의 등장
그런데 이 완벽했던 분할 전략에 AI 라는 변수가 등장했습니다. 딥러닝 트레이닝과 추론은 FP64가 필요 없습니다. 오히려 FP32면 충분하고, 최근에는 FP16, BF16, 심지어 FP8까지 사용하는 추세입니다.
갑자기 저렴한 소비자용 GPU가 ‘가성비 최고의 AI 머신’으로 돌변한 겁니다. 연구소와 스타트업들이 비싼 Tesla 카드 대신 RTX 3090/4090을 서버실에 꽂기 시작했죠. 이에 Nvidia가 어떻게 대응했는지 기억하시나요? 2017년, 기술적 제한 대신 EULA(최종 사용자 라이선스 계약)를 변경 하여 소비자용 카드의 데이터센터 사용을 금지해버렸습니다. 기술적 해자가 무너지니 법적 해자를 판 셈입니다.
3. Emulation: 하드웨어를 소프트웨어로 때우다
그렇다면 FP64가 꼭 필요한 HPC 워크로드는 어떨까요? 여기서 흥미로운 기술적 우회로가 등장합니다. 바로 Emulation 입니다.
전통적으로는 FP64 변수 하나를 두 개의 FP32 변수(a_hi, a_lo)로 쪼개서 연산하는 방식을 썼습니다. 정밀도는 약간 손해 보지만(53비트 -> 48비트 mantissa), FP32 처리량이 워낙 압도적이라 에뮬레이션 오버헤드를 감안해도 이득인 경우가 많았습니다.
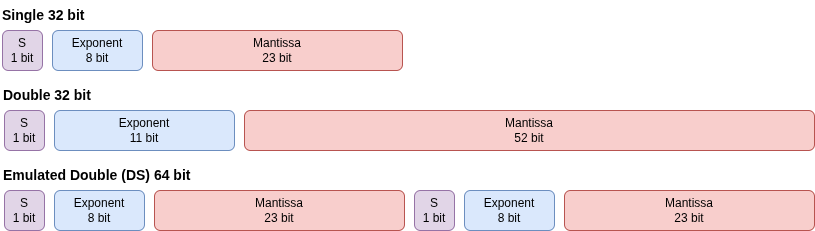
최근에는 Ozaki Scheme 이 주목받고 있습니다. 이 방식은 행렬 곱셈(Matrix Multiplication)에서 Tensor Core를 활용합니다. FP64 입력을 쪼개서 고속 FP8/FP4 텐서 코어에 태우고, 그 결과를 다시 합치는 방식입니다. Nvidia가 최근 cuBLAS에 이 기능을 추가했다는 것은 시사하는 바가 큽니다.
4. Blackwell Ultra (B300): 엔터프라이즈마저 FP64를 버리다
이번 글의 핵심은 여기입니다. Nvidia의 최신 엔터프라이즈 GPU인 Blackwell Ultra (B300) 의 스펙이 공개되었는데, 충격적이게도 FP64:FP32 비율이 1:64 로 떨어졌습니다.
기존 B200이 37 TFLOPS였는데, B300은 1.2 TFLOPS로 급락했습니다. 엔터프라이즈 GPU가 소비자용 GPU와 동일한 FP64 비율을 가지게 된 것입니다. 왜일까요?
이유는 간단합니다. AI가 돈이 되기 때문입니다. 다이(Die) 면적은 한정되어 있고, FP64 유닛을 박을 자리에 FP4 텐서 코어를 더 넣는 것이 훨씬 이득이라는 계산이 선 것입니다. 부족한 FP64 성능은 위에서 언급한 Ozaki Scheme 같은 에뮬레이션으로 때우면 되니까요.
5. 마치며: 경계선의 이동
과거 15년 동안 GPU 시장을 나누는 기준은 “FP64가 되느냐 안 되느냐”였습니다. 하지만 이제 그 기준은 무의미해졌습니다. 엔터프라이즈 하드웨어조차 물리적인 FP64 유닛을 들어내고 있습니다.
제 개인적인 견해로는, 이것은 순수 HPC(High Performance Computing)의 종말 이라기보다 AI 중심 컴퓨팅으로의 완전한 전환 을 의미합니다. 과학적 시뮬레이션조차 이제는 깡성능의 FP64 연산보다는 AI 기반의 근사(Approximation)나 텐서 코어를 활용한 에뮬레이션으로 넘어가는 과도기에 있습니다.
RTX 5090의 FP64 성능이 낮다고 실망할 필요 없습니다. 이제 수천만 원짜리 서버용 GPU도 똑같은 길을 걷고 있으니까요. 우리가 알던 ‘GPU’의 정의가 다시 한번 바뀌고 있습니다.