Diffusion Models Finally Beat Autoregressive? A Deep Dive into CDLM
LLM 인퍼런스 최적화 작업을 해보신 분들이라면 공감하시겠지만, Autoregressive(AR) 모델의 본질적인 한계는 명확합니다. 토큰을 하나씩 순차적으로 뱉어내야 한다는 점, 그로 인해 GPU의 병렬 처리 능력을 온전히 활용하지 못하고 Memory Bandwidth Bound 상태에 머무른다는 점이죠.
최근 Together.ai에서 발표한 Consistency Diffusion Language Models (CDLM) 논문을 읽어보면서, 어쩌면 우리가 당연하게 여기던 ‘Next Token Prediction’의 시대가 저물고 있을지도 모른다는 생각이 들었습니다. 오늘은 이 기술이 왜 중요한지, 그리고 엔지니어링 관점에서 어떤 의미가 있는지 깊게 파헤쳐 보겠습니다.
왜 굳이 Diffusion인가?
이미지 생성 분야에서는 Stable Diffusion이 표준이 되었지만, 텍스트 분야에서 Diffusion 모델(DLM)은 그동안 ‘가능성은 있지만 실용성은 없는’ 연구 주제였습니다. 가장 큰 이유는 두 가지입니다.
- KV Cache 불가능: 기존 DLM은 양방향(Bidirectional) Attention을 사용합니다. 즉, 매 스텝마다 전체 시퀀스를 다시 계산해야 하니 $O(L^2)$ 연산 비용이 발생합니다. AR 모델처럼 KV Cache를 쌓아두고 재사용하는 게 불가능했죠.
- 너무 많은 스텝: 고품질 텍스트를 얻으려면 수천 번의 Denoising step이 필요한데, 이걸 줄이면 품질이 급격히 떨어집니다.
하지만 이번에 발표된 CDLM은 이 두 가지 문제를 아주 영리하게 해결했습니다. 결과적으로 14.5배 더 빠른 속도 를 달성했고요.
CDLM의 핵심: Block-wise Caching과 Consistency
이 논문의 핵심은 ‘타협’과 ‘최적화’의 절묘한 조화입니다.
1. Block-wise KV Caching (타협의 미학)
완전한 양방향 Attention을 포기하고, Block 단위의 Causal Masking 을 도입했습니다. 이게 신의 한 수입니다.
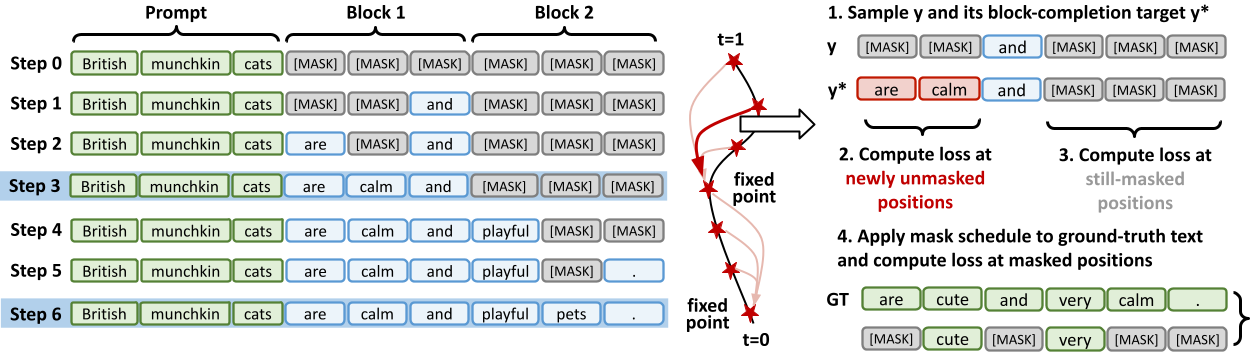
- Inter-block (블록 간): AR 모델처럼 작동합니다. 이전 블록들이 완료되어야 다음 블록을 생성하고, 완료된 블록의 KV Cache는 저장(Freeze)됩니다.
- Intra-block (블록 내): 블록 내부(예: 32토큰)에서는 Diffusion 방식으로 병렬 생성합니다.
즉, 전체 문맥을 다시 계산할 필요 없이, 완료된 블록은 캐싱하고 현재 생성 중인 블록만 반복 연산 하면 되는 구조를 만든 겁니다. 덕분에 기존 AR 인퍼런스 파이프라인에 꽤 쉽게 통합이 가능해졌습니다.
2. Consistency Distillation (속도의 핵심)
구조를 바꿨으니 이제 속도를 높일 차례입니다. ‘Consistency Model’ 개념을 도입해서, 모델이 여러 스텝을 거쳐야 갈 수 있는 Denoising 경로를 한 번에 점프하도록 학습시켰습니다.
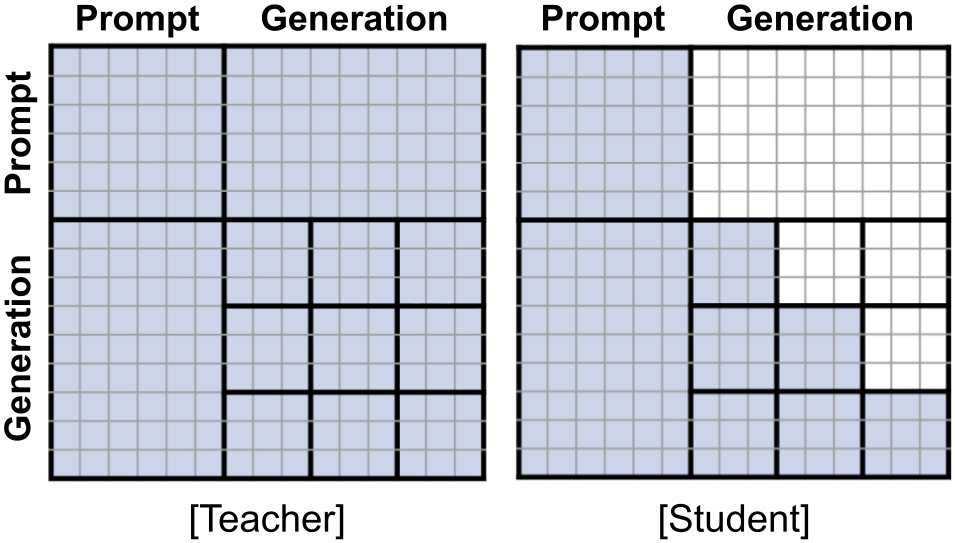
쉽게 말해, “100번 고쳐서 정답을 만들지 말고, 100번 고친 결과를 예측해 봐”라고 학생 모델(Student)을 가르치는 식입니다. 이를 통해 퀄리티 저하 없이 추론 스텝을 획기적으로 줄였습니다.
시스템 관점에서의 분석: Arithmetic Intensity
제가 이 논문에서 가장 인상 깊게 본 부분은 바로 하드웨어 효율성 분석입니다. 엔지니어라면 이 차트를 주목해야 합니다.
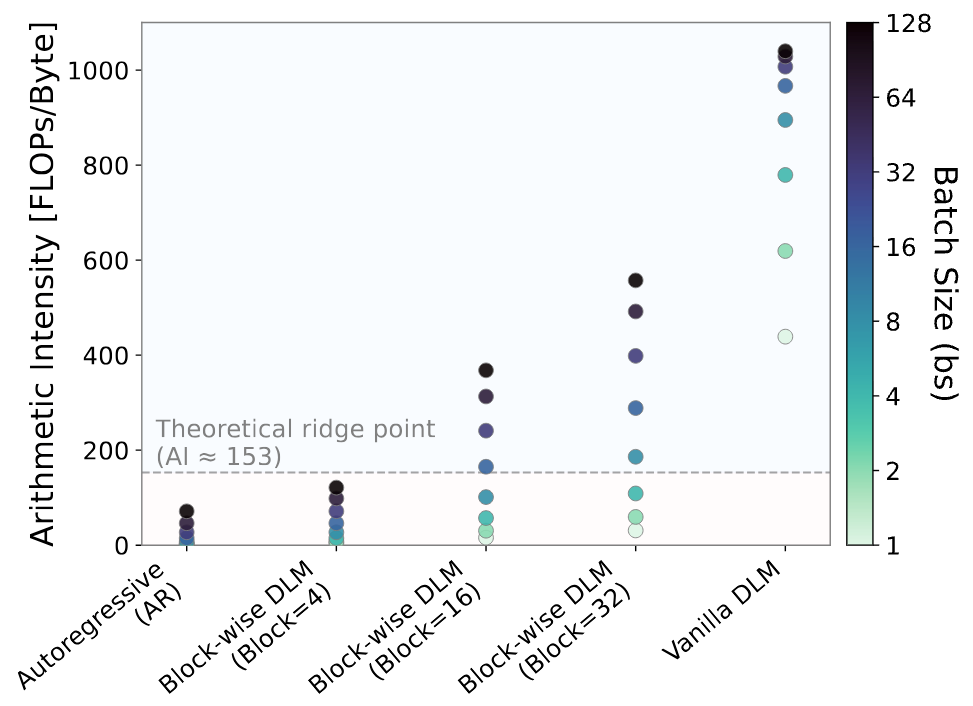
- AR 모델 (파란선): Batch Size 1에서 Arithmetic Intensity(AI)가 매우 낮습니다. 즉, GPU가 연산은 안 하고 메모리에서 데이터 가져오느라 놀고 있다는 뜻입니다. (Memory Bound)
- Vanilla DLM (초록선): 반대로 연산량이 너무 많아서 Compute Bound에 걸립니다. 느릴 수밖에 없죠.
- CDLM (주황/빨강선): 그 중간 지점(Sweet Spot)을 정확히 타격합니다. 블록 내 병렬 처리로 연산 밀도를 높여 메모리 대역폭 병목을 완화하면서도, 전체 시퀀스를 재연산하지 않아 연산 과부하를 막았습니다.
이건 특히 Small Batch Inference 환경(예: 로컬 LLM, 온디바이스 AI, 실시간 에이전트)에서 엄청난 이점을 가집니다. 배치 사이즈를 억지로 키우지 않아도 하드웨어 효율을 뽑아낼 수 있다는 뜻이니까요.
Hacker News의 반응과 나의 생각
Hacker News의 반응도 뜨겁습니다. “드디어 내 책상 밑 컴퓨터에서 돌릴 만한 Diffusion 언어 모델이 나오는가?”라는 기대 섞인 반응이 많더군요.
“Diffusion language models seem poised to smash purely autoregressive models. I’m giving it 1-2 years.”
한 유저는 이를 ‘나트륨 이온 배터리 vs 리튬 이온 배터리’에 비유했습니다. AR 모델(리튬)이 상용화와 최적화에서 훨씬 앞서 있지만, 이론적 한계가 명확한 반면, Diffusion(나트륨)은 이제 막 가능성을 보여주고 있다는 거죠.
제 개인적인 평가는 이렇습니다:
솔직히 그동안 “AR은 끝났다”라고 주장하는 논문들을 많이 봤지만, 실전 배포(Serving) 관점에서 AR의 KV Caching 효율을 이기는 건 불가능에 가까웠습니다. 하지만 CDLM은 그 ‘캐싱’ 문제를 해결하면서 Diffusion의 장점(병렬 생성, Infilling 등)을 가져왔다는 점에서 Game Changer 가 될 잠재력이 충분합니다.
물론 아직은 ‘Post-training’ 레시피 수준이고, 405B 급의 초대형 모델에서도 이 효율이 유지될지는 지켜봐야 합니다. 하지만 만약 여러분이 Latency-sensitive한 애플리케이션을 개발 중이라면, 이 기술의 발전 추이를 반드시 주시해야 합니다. 14배 빠르다는 건, 사용자 경험이 완전히 달라진다는 뜻이니까요.