LLM을 실리콘에 박제하다: Taalas의 17,000 TPS 칩이 던지는 충격과 의문
엔지니어로서 커리어를 쌓다 보면, 가끔 “이건 물리법칙을 무시하는 건가?” 싶을 정도로 황당한 스펙을 들고 나오는 회사들을 마주하게 됩니다. 대부분은 투자금을 노린 허풍이지만, 아주 드물게 게임의 규칙 자체를 바꿔버리는 경우도 있죠.
오늘 소개할 Taalas 라는 회사가 바로 그 경계선에 서 있습니다. 이들은 최근 Llama 3.1 8B 모델을 실리콘 칩에 말 그대로 ‘하드와이어링(Hardwiring)’ 해서 내놓았습니다. 결과는 충격적입니다. 초당 17,000 토큰(tokens/sec). 우리가 흔히 쓰는 GPU 기반 추론보다 약 10배에서 20배 빠른 속도입니다.
단순히 빠르다는 말로는 부족합니다. 이건 LLM 인프라의 패러다임을 ‘범용 연산’에서 ‘전용 회로’로 옮기려는 시도입니다. 오늘 포스팅에서는 Taalas의 아키텍처가 왜 기술적으로 흥미로운지, 그리고 Hacker News의 시니어 엔지니어들은 이 미친 시도를 어떻게 보고 있는지 깊게 파헤쳐 보겠습니다.

1. 범용성의 포기, 극한의 효율
우리가 흔히 쓰는 NVIDIA H100 같은 GPU는 ‘범용성’의 끝판왕입니다. 어떤 모델이든 메모리에 올리고, 명령어를 가져와(Fetch), 해석하고(Decode), 실행(Execute)합니다. 이 유연함 덕분에 매일 쏟아지는 새로운 논문들을 바로바로 테스트할 수 있죠.
하지만 Taalas는 이 과정을 비효율적이라고 봅니다. 그들의 접근 방식은 “모델의 가중치(Weights)와 연산 그래프를 아예 트랜지스터로 구워버리자” 는 것입니다. 즉, 소프트웨어가 아니라 하드웨어 자체가 Llama 3.1이 되는 겁니다.
Memory Wall의 붕괴
현대 AI 가속기의 가장 큰 병목은 컴퓨팅 파워가 아니라 메모리 대역폭(Memory Wall) 입니다. HBM(High Bandwidth Memory)을 층층이 쌓아 올리는 이유도 이 때문이죠. 데이터가 칩 밖(Off-chip)에 있는 DRAM에서 칩 안(On-chip)으로 이동하는 비용이 너무 비쌉니다.
Taalas는 이 문제를 무식하지만 확실한 방법으로 해결했습니다.
- No DRAM, No HBM: 모든 모델 파라미터를 칩 내부의 SRAM에 저장합니다.
- Direct Data Flow: 메모리와 연산 유닛의 구분이 없습니다. 데이터가 회로를 통과하면 그게 곧 추론입니다.
이 구조 덕분에 전력 소모는 10분의 1, 생산 비용은 20분의 1로 줄었다고 주장합니다. 복잡한 패키징이나 수냉 쿨링도 필요 없습니다. 그냥 거대한 SRAM 덩어리와 로직이 섞여 있는 칩 하나면 됩니다.
2. 17,000 TPS가 의미하는 것
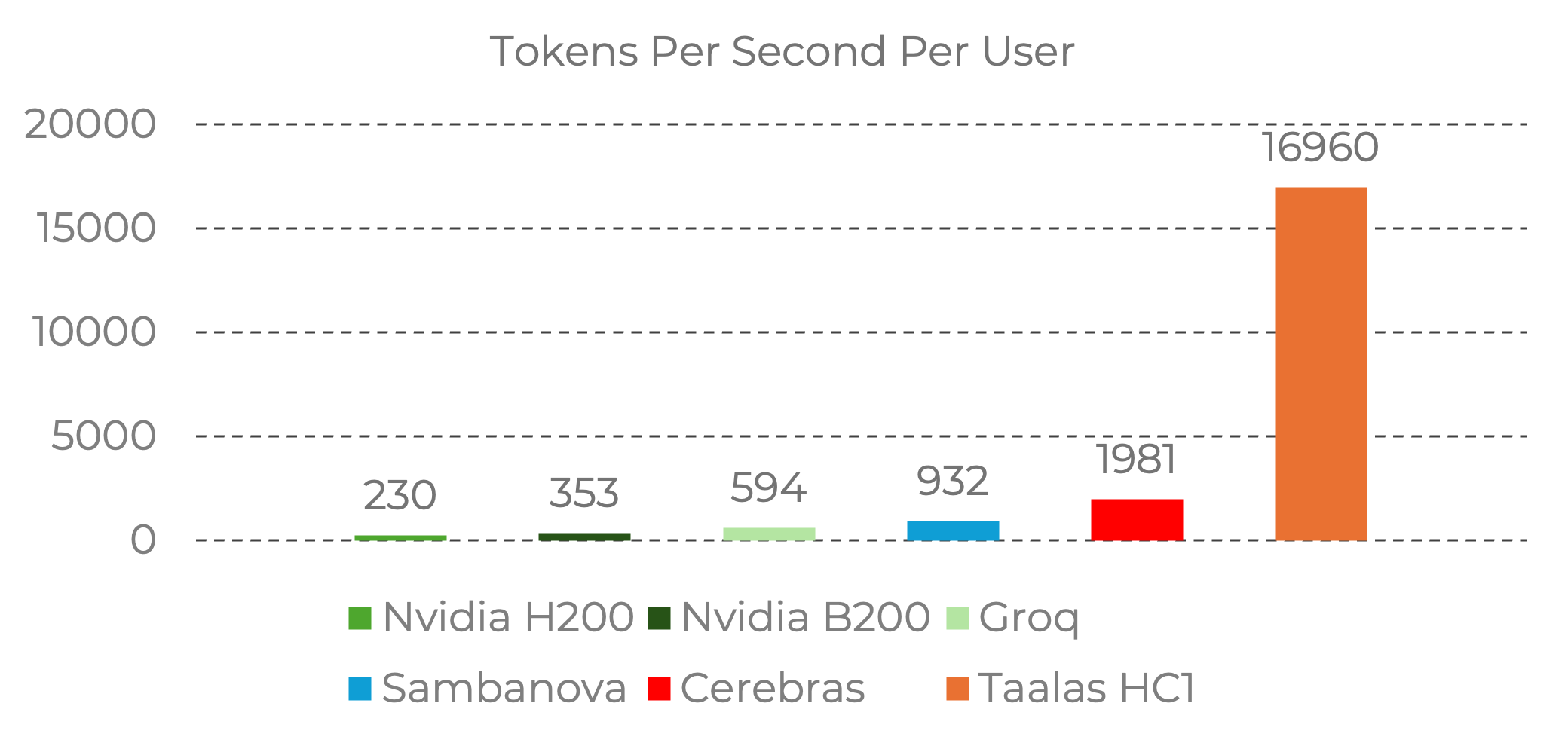
초당 17k 토큰이라는 숫자는 단순히 “채팅이 빨라진다”는 수준이 아닙니다. Hacker News의 한 유저는 이를 두고 “양적 변화가 질적 변화를 만들어내는 순간(Quantitative change becomes qualitative change)” 이라고 표현했습니다.
- Real-time Voice Agent: 현재의 음성 비서들은 Latency 때문에 대화가 뚝뚝 끊깁니다. 1ms 미만의 Latency는 인간과 구분이 불가능한 실시간 대화를 가능하게 합니다.
- Agentic Loops: AI 에이전트가 복잡한 작업을 수행하려면 수천 번의 내부 독백(Internal Monologue)과 추론 과정을 거쳐야 합니다. 지금 속도로는 커피 한 잔 마시고 와야 결과가 나오지만, 17k TPS라면 순식간에 끝납니다.
3. Hacker News의 기술적 논쟁들
이 발표를 두고 Hacker News에서는 꽤 심도 있는 기술적 토론이 오갔습니다. 주요 쟁점을 정리해 드립니다.
쟁점 1: 칩 하나인가, 여러 개인가?
초기에는 “8B 모델을 돌리려면 칩 10개가 필요한 것 아니냐”는 오해가 있었지만, 기술적 분석 결과 단일 칩(Single Chip) 일 가능성이 높습니다.
- Die Size: 약 880mm² (TSMC 6nm 공정의 Reticle limit에 가까움)
- Memory: 3-bit Quantization을 적용하면 8B 모델은 약 3GB의 용량이 필요합니다. 이는 거대한 다이 하나에 SRAM으로 꽉 채우면 물리적으로 구현 가능한 수준입니다.
- Quantization: Taalas는 3-bit/6-bit 혼합 정밀도를 사용합니다. 이로 인한 품질 저하는 분명 존재하겠지만, 속도를 위해 타협한 부분입니다. 차기작은 FP4를 지원한다고 합니다.
쟁점 2: 유연성(Flexibility)의 부재와 2개월의 리드 타임
가장 큰 비판점은 “모델이 업데이트되면 칩을 갖다 버려야 한다”는 점입니다. Llama 4가 나오면 이 칩은 고철이 됩니다. Taalas는 “새 모델을 실리콘으로 구현하는 데 2개월이면 충분하다”고 주장하지만, 반도체 공정을 아는 사람들은 이 ‘2개월’이라는 숫자에 대해 회의적입니다.
하지만 한 유저의 통찰이 인상 깊었습니다:
“이들의 진짜 제품은 칩이 아니라, 모델을 회로로 변환하는 자동화 컴파일러(Automation Compiler) 다.”
만약 이들이 Verilog/VHDL 코드를 자동으로 생성하고 검증하는 파이프라인을 완벽하게 구축했다면, 2개월은 불가능한 숫자가 아닐 수도 있습니다.
쟁점 3: 킬러 앱은 ‘Speculative Decoding’
개인적으로 가장 동의하는 부분입니다. 이 칩을 메인 두뇌로 쓰기엔 유연성이 부족합니다. 하지만 Speculative Decoding(추측 디코딩) 용 드래프트 모델(Draft Model)로 쓴다면 어떨까요?
- 작동 원리: Taalas 칩이 초고속으로 예상 토큰들을 생성하고, 거대한 H100 클러스터의 더 똑똑한 모델이 이를 검증만 합니다.
- 이점: 기존 인프라를 갈아엎지 않고도 전체 추론 속도를 획기적으로 높일 수 있습니다. H100의 비싼 자원을 ‘생성’이 아닌 ‘검증’에만 쓰게 하여 효율을 극대화하는 것이죠.
4. 엔지니어의 시선: 혁신인가, 틈새시장인가?
솔직히 말해, Taalas의 접근 방식은 2010년대 초반 비트코인 채굴이 CPU에서 ASIC으로 넘어가던 시기를 떠올리게 합니다. 알고리즘(모델 아키텍처)이 어느 정도 안정화되었기 때문에 가능한 시도입니다. Transformer 아키텍처가 당분간 바뀌지 않을 것이라는 베팅이기도 하죠.
하지만 우려되는 점도 분명합니다.
- 모델 수명 주기: LLM은 여전히 너무 빨리 변합니다. 하드웨어가 소프트웨어의 발전 속도를 따라갈 수 있을까요?
- 품질 저하: 3-bit Quantization은 생각보다 품질 손실이 큽니다. 벤치마크 점수는 비슷할지 몰라도, 실제 사용감(Vibe check)은 다를 수 있습니다.
그럼에도 불구하고, 저는 이 시도가 매우 반갑습니다. 모두가 NVIDIA만 쳐다보며 HBM 수급난을 탓하고 있을 때, “메모리 계층 구조 자체를 없애버리자” 는 과격한 발상은 엔지니어링의 본질을 보여줍니다.
결론적으로, Taalas 칩이 범용 GPU를 대체하지는 못할 겁니다. 하지만 특정 도메인(Edge Device, 초저지연 음성 봇, 대규모 추론 농장의 가속기)에서는 독보적인 위치를 차지할 가능성이 큽니다. 만약 여러분이 수천 개의 동시 접속을 처리해야 하는 AI 서비스를 운영 중이라면, 이들의 API가 열렸을 때 한 번쯤 테스트해 볼 가치는 충분합니다.
저도 신청 폼을 넣으러 가야겠습니다. 17,000 TPS가 주는 ‘속도감’이 코딩 경험을 어떻게 바꿀지, 직접 느껴보고 싶거든요.