Mercury 2: Autoregressive의 한계를 뚫는 Diffusion LLM, 그리고 1009 t/s의 충격
최근 LLM 씬을 지켜보다 보면, 솔직히 ‘또 새로운 모델이야?‘라는 피로감이 드는 게 사실입니다. 대부분은 Transformer 아키텍처 위에서 파라미터 수를 조절하거나, 데이터 셋을 정제하거나, 혹은 추론 하드웨어(Groq, Cerebras 등)를 갈아 넣는 식의 최적화였으니까요.
하지만 오늘 소개할 Inception Labs의 Mercury 2 는 좀 다릅니다. 이 녀석은 근본적인 아키텍처 를 건드렸습니다. 바로 ‘Diffusion’입니다.
이미지 생성 AI(Stable Diffusion 등)에서나 보던 그 Diffusion을 텍스트 생성에 적용해, 초당 1,009 토큰 이라는 말도 안 되는 속도를 찍었습니다. 오늘은 이 모델이 기술적으로 어떤 의미를 가지는지, 그리고 현업 엔지니어 관점에서 이게 진짜 ‘물건’인지 뜯어보겠습니다.
Autoregressive의 병목과 Diffusion의 등장
우리가 쓰는 GPT, Claude, Llama 등 거의 모든 메이저 LLM은 Autoregressive(자기회귀) 방식입니다. 즉, 문장을 만들 때 A 다음에 B, B 다음에 C를 예측하며 왼쪽에서 오른쪽으로 한 땀 한 땀 토큰을 찍어냅니다. 이걸 병렬화하는 건 불가능에 가깝습니다. 앞 토큰이 나와야 뒤 토큰을 계산하니까요.
Mercury 2는 이 판을 뒤집었습니다.
- Autoregressive: 타자기(Typewriter). 한 글자씩 순서대로 침.
- Diffusion: 편집자(Editor). 초안 전체를 동시에 펼쳐놓고, 노이즈를 제거하며 문장을 다듬어감.
Inception Labs는 이를 “Parallel Refinement”라고 부릅니다. 모든 토큰을 동시에 생성하고, 몇 번의 스텝을 거쳐 수렴시킵니다. 결과적으로 시퀀스 길이에 따른 레이턴시 증가가 거의 없는, 완전히 다른 속도 곡선을 만들어냅니다.
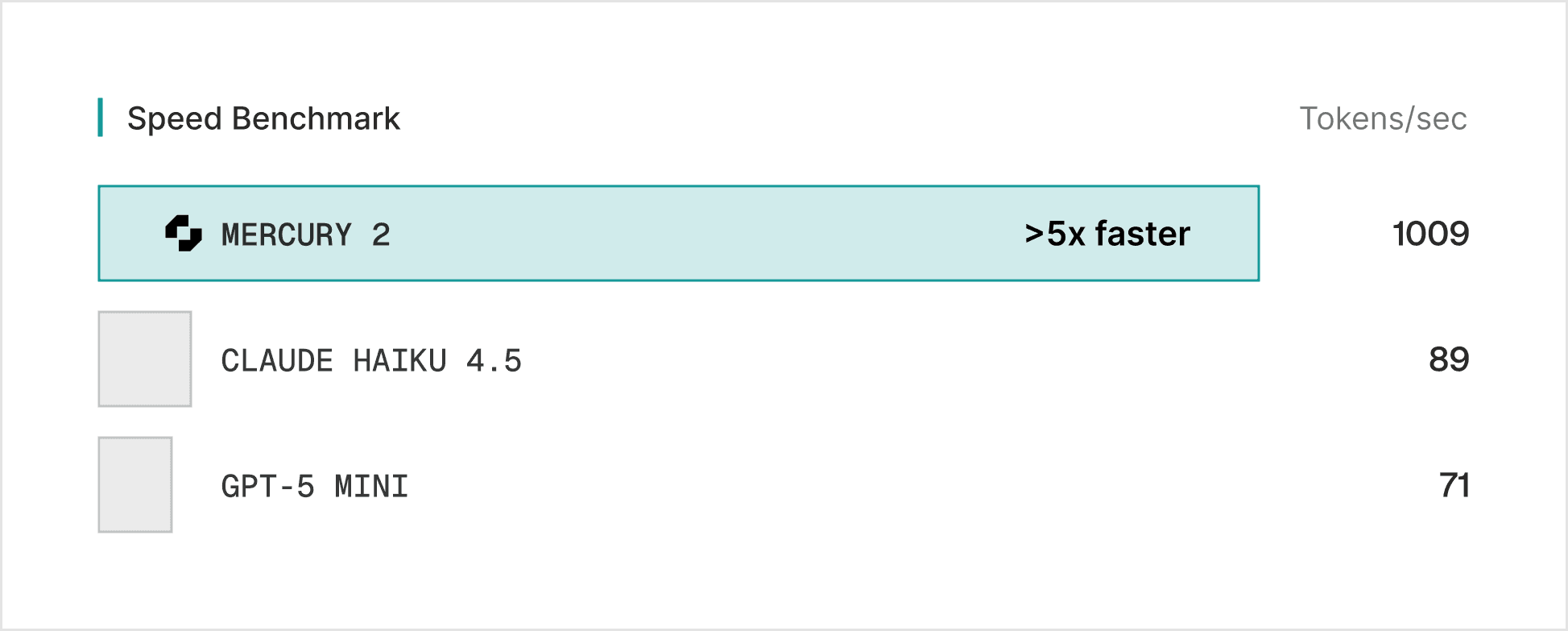
1009 t/s가 엔지니어링에 미치는 영향
단순히 채팅이 빨라지는 게 아닙니다. Hacker News의 volodia (Inception Labs 공동창업자)가 언급했듯, 이 속도는 Agentic Loop 의 설계를 바꿉니다.
- 코드 자동완성 및 리팩토링: 개발자 경험(DX)에서 300ms와 1s의 차이는 ‘도구’와 ‘방해꾼’의 차이입니다. Zed 에디터 창업자가 “내 생각의 일부처럼 느껴진다”고 한 건 과장이 아닐 겁니다.
- RAG & Search: 검색 결과를 요약하고 reranking 하는 과정에서 병목이 사라집니다.
- 음성 인터페이스: 사람이 말하는 속도에 맞춰 실시간으로 대화하려면 추론 속도가 깡패여야 합니다.
특히 제가 주목하는 건 Agentic Workflow 입니다. 기존에는 LLM이 느리고 비싸서 ‘한 번에 잘하기’를 기도하며 프롬프트를 깎았습니다. 하지만 Mercury 2처럼 빠르고 싸다면 ($0.25/1M 입력), 그냥 10번 생성해서 검증 로직(Compiler, Test Code 등)으로 필터링하는 게 훨씬 이득일 수 있습니다.
Hacker News의 반응: “속도가 곧 퀄리티다?”
Hacker News 스레드에서는 꽤 날카로운 토론들이 오갔습니다. 몇 가지 핵심 쟁점을 정리해 봅니다.
1. 하드웨어 vs 소프트웨어
Groq이나 Cerebras는 하드웨어 레벨에서 연산 속도를 높여 Autoregressive 모델을 가속합니다. 반면 Mercury는 소프트웨어(아키텍처)로 접근했죠. 한 유저는 “Groq은 칩을 팔지만, Mercury는 방법론을 판다. 이게 검증되면 다른 랩들도 전부 Diffusion으로 갈아탈 것”이라고 예측했습니다.
2. 지능(Intelligence) vs 속도
가장 큰 의문은 “그래서 멍청한데 빠르기만 한 거 아냐?”입니다. Inception Labs 측은 Mercury 2가 Claude Haiku, GPT-4o-mini 급의 지능을 가진다고 솔직하게 인정했습니다. 즉, 복잡한 추론(Reasoning)보다는 빠릿빠릿한 작업 처리에 특화된 모델입니다.
한 유저는 흥미로운 메트릭을 제안했습니다:
“Intelligence per second (초당 지능) 지표가 필요하다.”
3. 실전 압축 사용법
어떤 유저는 “Frontier 모델(o1, Opus)로 계획(Planning)을 세우고, Mercury로 실행(Generating)하는 하이브리드 패턴”을 제안했습니다. 저도 이 의견에 동의합니다. 모든 task에 Einstein이 필요하진 않습니다. 손이 빠른 인턴이 필요할 때가 더 많죠.
개인적인 평가와 우려
솔직히 데모 사이트가 트래픽 폭주로 터져버린 건 좀 아쉽습니다(HN에서도 불만이 많더군요). 하지만 기술적 방향성은 매우 흥미롭습니다.
제가 현업에서 느끼는 가장 큰 병목은 LLM의 Latency 입니다. 사용자가 기다리는 3~5초는 영겁의 시간입니다. 만약 Mercury 2가 주장하는 대로 Haiku 급의 성능을 5배 빠른 속도로 제공한다면, 특히 JSON 모드 나 Function Calling 이 안정적이라면, 백엔드 로직에 바로 투입할 의향이 있습니다.
다만, Diffusion 방식이 Hallucination(환각) 제어에 얼마나 효과적일지는 검증이 필요합니다. 이미지 생성에서 손가락 6개가 나오듯, 텍스트에서도 묘한 노이즈가 낄 가능성을 배제할 수 없으니까요.
결론: 찍먹해볼 가치는 충분하다
Mercury 2는 ‘만능 AI’를 지향하지 않습니다. 대신 “속도가 기능이다(Speed is a feature)” 라는 명제를 증명하려고 합니다. OpenAI 호환 API를 제공한다고 하니, 기존 랭체인(LangChain) 파이프라인에서 model_name만 바꿔서 테스트해 볼 가치는 충분해 보입니다.
특히 RAG 파이프라인이나 실시간 봇을 운영 중인 CTO라면, 이 새로운 ‘속도의 축’을 반드시 주시해야 합니다.
References: