브라우저의 시간을 조작해 완벽한 비디오를 렌더링하는 방법 (feat. Replit의 꼼수와 한계)
최근 Replit에서 꽤 흥미로운, 그리고 동시에 여러 커뮤니티에서 논란이 되고 있는 엔지니어링 블로그 글을 하나 발행했습니다. 요구사항은 단순해 보입니다. ‘애니메이션이 포함된 임의의 웹 페이지를 MP4 비디오 파일로 변환하라.’
15년 넘게 엔지니어링을 해오면서 이런 류의 요구사항을 수없이 마주해 봤지만, 브라우저 환경에서 이를 완벽하게 구현하는 것은 지옥에 가깝습니다. 단순히 Headless 브라우저를 띄우고 화면을 녹화하면 될 것 같지만, 브라우저의 렌더링 엔진은 실시간(Real-time) 시스템입니다. 시스템 부하가 오면 프레임을 스킵하고, 애니메이션은 Wall-clock 시간에 종속됩니다. 결국 녹화된 결과물은 프레임이 뚝뚝 끊기는 참담한 영상이 되기 십상이죠.
Replit 팀은 이 문제를 해결하기 위해 브라우저의 ‘시간’ 자체를 속이는 극단적인 방식을 선택했습니다. 오늘 포스팅에서는 이들이 어떤 기상천외한 꼼수를 썼는지 기술적으로 딥다이브 해보고, Hacker News에서 왜 이 글이 비판을 받고 있는지도 함께 짚어보겠습니다.
왜 Remotion을 쓰지 않았을까?
웹을 비디오로 렌더링한다고 할 때 가장 먼저 떠오르는 도구는 당연히 Remotion 입니다. React 컴포넌트 기반으로 완벽하게 Deterministic(결정론적)인 렌더링을 보장하죠.
하지만 Replit의 유즈케이스에는 맞지 않았습니다. 이들의 AI 에이전트는 특정 프레임워크에 종속되지 않은, 날것의 CSS 애니메이션이나 <canvas>, 심지어 정체불명의 Confetti 라이브러리가 포함된 ‘임의의 URL’을 던져주고 완벽한 비디오를 뽑아내야 했기 때문입니다. 즉, 외부에서 임의의 웹 페이지에 강제로 결정론적 환경을 주입해야만 했습니다.
핵심 트릭: 가상 클럭 (Virtual Clock) 주입
이들이 선택한 해결책의 핵심은 약 1,200줄짜리 JavaScript 파일을 캡처하려는 모든 페이지에 주입하여 브라우저의 시간 관련 API를 전부 몽키패칭(Monkey-patching)하는 것입니다.
setTimeout, setInterval, requestAnimationFrame, Date.now(), performance.now() 등 애니메이션 타이밍에 관여하는 모든 API를 가로채서 자신들이 통제하는 ‘가짜 시계’로 대체했습니다. 실제 렌더링에 500ms가 걸리든 1초가 걸리든, 브라우저 입장에서는 매 프레임마다 정확히 1000/fps 밀리초(60fps 기준 약 16.67ms)만 시간이 흐른 것으로 착각하게 만드는 것이죠.
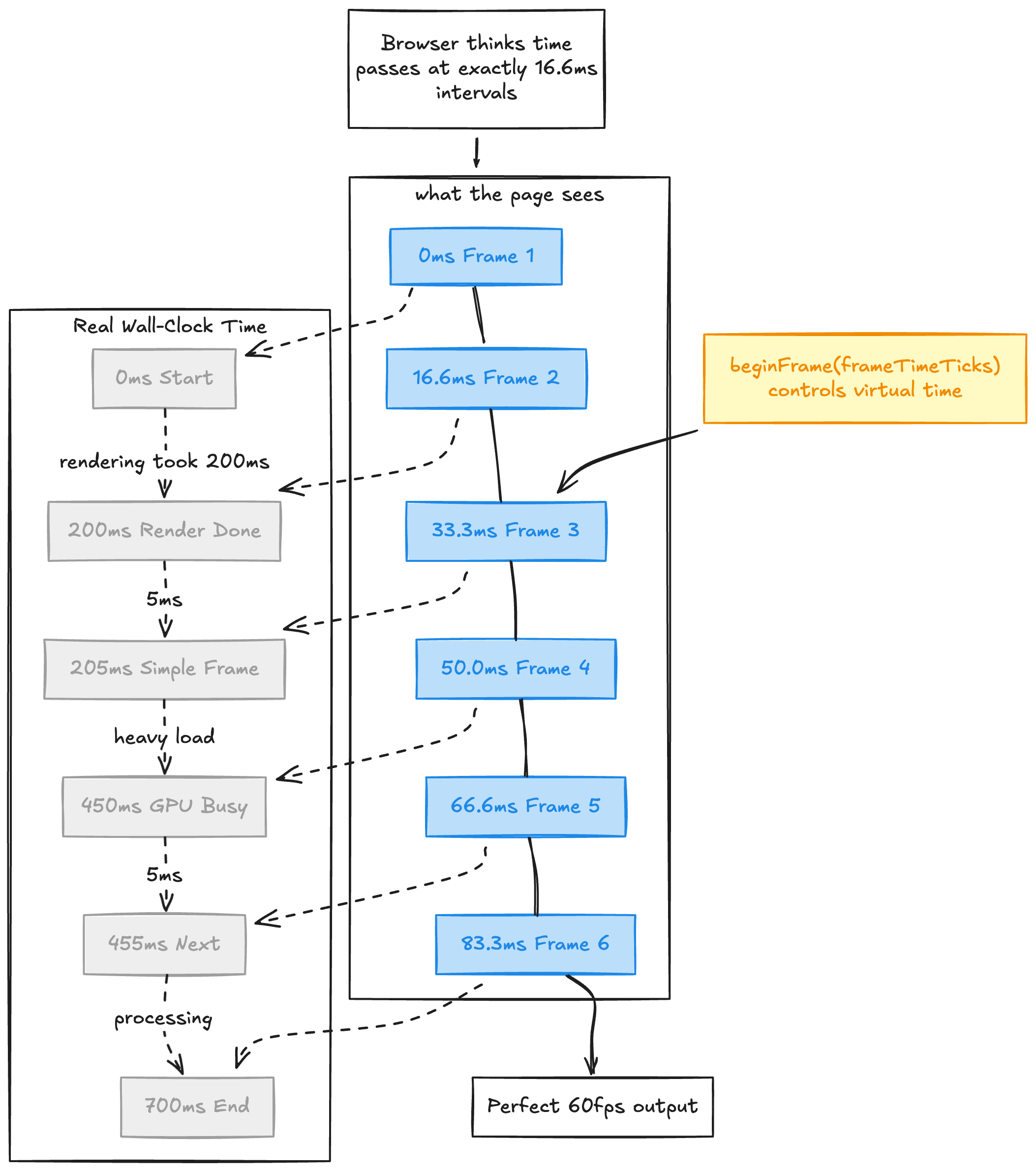
프레임 루프의 핵심 로직은 다음과 같습니다.
nextFrame() {
const loop = async () => {
await seekCSSAnimations(currentTime); // CSS 동기화
await seekMedias(); // 비디오 동기화
currentTime += frameInterval; // 시계 틱 전진
callIntervalCallbacks(currentTime); // setInterval 실행
callTimeoutCallbacks(currentTime); // setTimeout 실행
callRAFCallbacks(currentTime); // rAF 실행
await captureFrame(); // 스크린샷 캡처
loop(); // 다음 프레임
};
loop();
}솔직히 이 코드를 보고 과거 Demoscene 시절 .kkapture 같은 툴들이 쓰던 방식이 떠올랐습니다. 완전히 새로운 개념은 아니지만, 현대의 복잡한 브라우저 환경에서 이를 억지로 구현해 낸 끈기 하나는 인정할 만합니다.
비디오와 오디오: 끔찍한 루브 골드버그 장치
시간을 통제한다고 끝이 아닙니다. Headless Chrome에서 <video> 태그의 재생은 프레임 단위의 완벽한 탐색(Seeking)을 보장하지 않습니다. 이를 해결하기 위해 이들이 구축한 5단계 파이프라인은 그야말로 광기에 가깝습니다.
- 1단계: DOM에서
<video>요소를 감지합니다. - 2단계: 서버 사이드에서 FFmpeg를 돌려 해당 비디오를 Fragmented MP4로 트랜스코딩합니다.
- 3단계: 브라우저 내에서
mp4box.js를 사용해 청크를 디먹싱합니다. - 4단계: WebCodecs API (또는 WASM 폴리필)를 사용해 프레임을 디코딩합니다.
- 5단계: 원본
<video>요소를<canvas>로 교체하고, 가상 클럭에 맞춰 디코딩된 프레임을 그립니다.
오디오 역시 마찬가지입니다. Headless 환경에서는 스피커 출력을 캡처할 수 없으므로, Web Audio API와 HTMLMediaElement의 진입점을 전부 몽키패칭하여 ‘어떤 오디오 파일이, 언제, 어느 정도의 볼륨으로 재생되는지’ 메타데이터만 가로챕니다. 이후 서버에서 FFmpeg 필터 체인을 사용해 오디오 트랙을 믹싱하는 방식을 택했습니다.
이 파이프라인을 실무에 적용한다고 상상해 보십시오. 당장 내일 브라우저 메이저 업데이트가 발생해 Web Audio API 내부 동작이 미세하게 바뀌거나, 프로그래밍 방식으로 생성된 OscillatorNode 같은 합성 오디오가 들어오면 이 시스템은 속수무책으로 무너집니다. 전형적인 ‘유지보수 지옥’이 열리는 구조입니다.
Hacker News의 냉담한 반응: LLM 냄새와 오픈소스 논란
기술적인 흥미로움과는 별개로, 이 블로그 포스트는 Hacker News에서 상당히 많은 비판을 받았습니다.
첫 번째 비판은 글의 톤앤매너 입니다. 수많은 시니어 엔지니어들이 이 글이 ChatGPT 같은 LLM으로 작성된 티가 너무 난다고 지적했습니다. “가상화된 시간 그 자체(virtualizing time itself)“라거나 “Headless Chrome의 변덕과 전쟁을 벌였다(waging war against headless Chrome’s quirks)” 같은 과장된 수사학은 실제 엔지니어들이 쓰는 언어가 아닙니다. 기술 블로그에서 진정성이 결여된 LLM 특유의 바이브가 느껴지면, 독자들은 그 기술의 깊이마저 의심하게 됩니다.
두 번째 비판은 오리지널리티 입니다. 글의 맨 마지막에 가서야 이 모든 아키텍처가 Vinlic의 오픈소스 프로젝트인 WebVideoCreator 에 기반하고 있음을 밝힙니다. 거인의 어깨 위에 섰다고 표현했지만, 사실상 핵심 아이디어(시간 API 몽키패칭, BeginFrame 캡처)를 그대로 가져다 쓰고 자신들의 클라우드 인프라에 맞춰 수정한 뒤 독점(Proprietary) 기술로 닫아버린 것에 대해 커뮤니티의 시선이 곱지 않습니다.
마지막으로, “그냥 OBS나 하드웨어 캡처를 쓰면 안 되나?” 라는 근본적인 의문이 제기되었습니다. 물론 Replit 측은 ‘완벽한 프레임 페이싱(Frame pacing)‘을 위해 이 복잡한 짓을 했다고 항변하겠지만, AI가 생성한 임의의 UI 데모 영상을 렌더링하기 위해 브라우저 엔진의 렌더링 파이프라인과 멱살잡이를 하는 것이 과연 올바른 엔지니어링 의사결정인지에 대해서는 저 역시 회의적입니다.
결론: 프로덕션 레벨인가, 거대한 장난감인가?
Replit의 이 시스템은 특정 목적(AI 에이전트의 결과물 시각화)을 달성하기 위해 브라우저의 본질을 거스르는 거대한 해킹입니다.
기술적으로는 훌륭한 탐구(Exploration)이며, WebCodecs와 가상 클럭을 활용한 동기화 기법 등은 분명 배울 점이 있습니다. 하지만 일반적인 기업 환경에서 이런 방식을 프로덕션에 도입하려 한다면 저는 결사반대할 것입니다. 브라우저는 실시간 렌더링을 위해 설계되었지, Deterministic 한 오프라인 렌더러가 되기를 원치 않습니다. 브라우저가 원하지 않는 일을 억지로 시키면, 결국 영원히 브라우저 업데이트를 쫓아가며 땜질을 해야 하는 기술 부채로 돌아오기 때문입니다.
References:
- Original Article: We Built a Video Rendering Engine by Lying to the Browser About What Time It Is
- Hacker News Thread: Discussion on HN