Mamba-3 리뷰: 학습 속도를 버리고 추론 효율을 선택한 SSM의 진화
최근 LLM 생태계의 무게 중심이 Pretraining에서 Post-training과 Deployment로 급격히 이동하고 있습니다. RLVR이나 Agentic workflow가 대세가 되면서, 우리가 프로덕션 환경에서 마주하는 진짜 괴물은 다름 아닌 Inference 비용과 Latency입니다.
작년에 Mamba-2가 나왔을 때를 기억하시나요? 당시에는 “학습 속도가 미쳤다”며 다들 열광했지만, 저는 약간 회의적이었습니다. 학습이 빠른 건 좋지만, 정작 서빙할 때 Memory-bound 문제로 GPU가 깡통이 되는 현상은 여전했거든요. 그런데 이번에 발표된 Mamba-3는 방향을 완전히 틀었습니다. 학습 속도라는 타이틀을 내려놓고, 철저하게 Inference 효율 에 집중했습니다.
왜 Mamba-2로는 부족했을까?
Mamba-2의 근본적인 한계는 학습 속도를 위해 내부 SSM 메커니즘을 너무 단순화했다는 점입니다. 디코딩 단계에서 GPU의 텐서 코어는 놀고 있는데, 메모리만 죽어라 퍼나르는 전형적인 Memory-bound 상태에 빠졌죠.
Mamba-3 팀은 “어차피 디코딩 때 GPU가 논다면, 그 남는 컴퓨팅 파워로 모델의 표현력을 극한으로 끌어올리자”는 매우 실용적인 엔지니어링 접근을 취했습니다.
- Expressive Recurrence: 기존의 단순화된 공식을 버리고 exponential-trapezoidal 이산화 방식을 도입해 다이내믹스를 풍부하게 만들었습니다.
- Complex-valued State Tracking: 상태 추적을 복소수 영역으로 확장해 더 복잡한 패턴을 기억하도록 했습니다.
- MIMO Variant: 제가 가장 감탄한 부분입니다. 여러 개의 SSM을 병렬로 모델링합니다. 학습 시간은 늘어나지만, 어차피 디코딩 시점에는 GPU 연산량이 남아돌기 때문에 Latency 증가 없이 정확도만 공짜로 올려버리는 마법을 부렸습니다.
과감한 아키텍처 다이어트
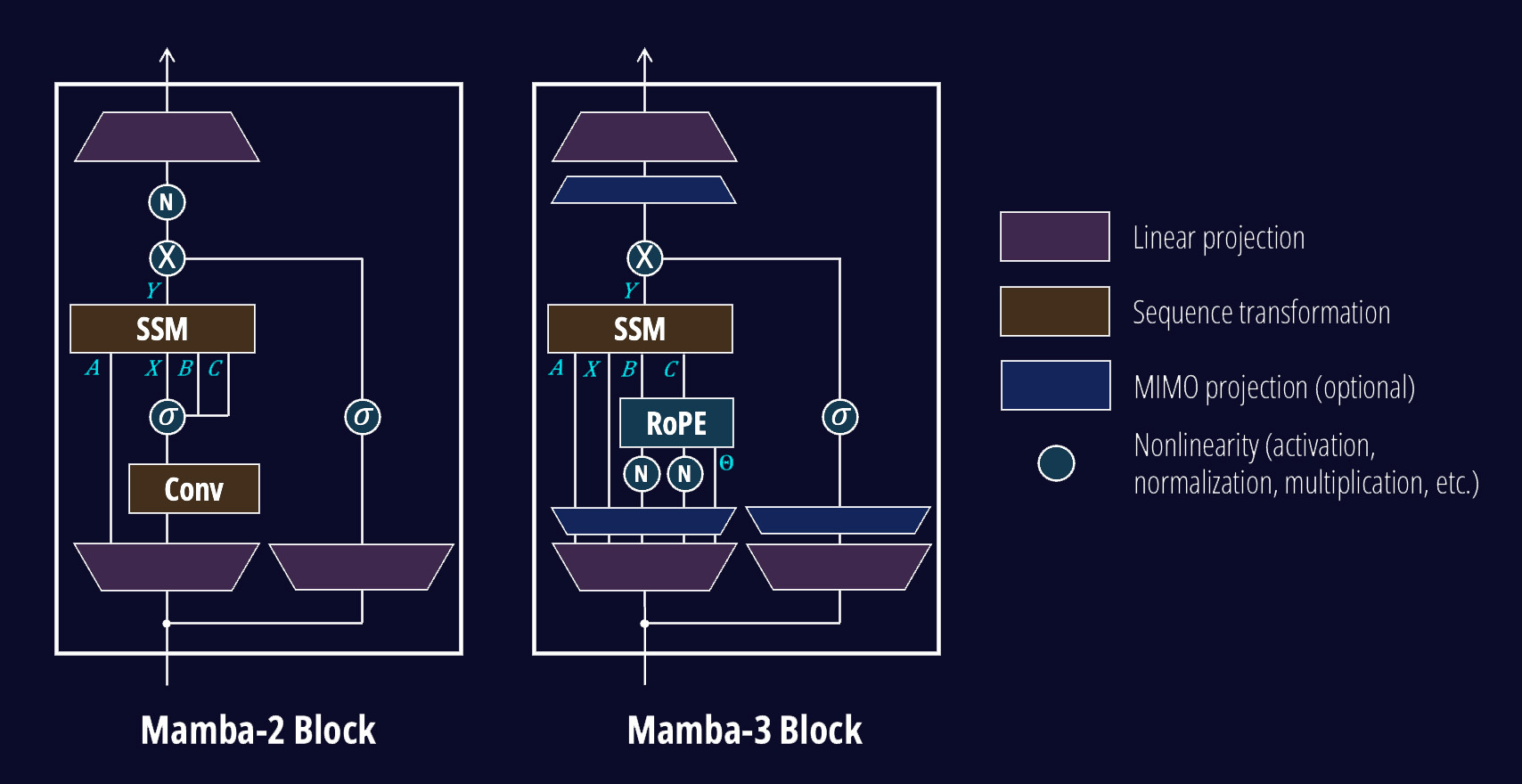
아키텍처에서도 꽤 과감한 칼질이 들어갔습니다. 가장 눈에 띄는 건 Mamba 시리즈의 상징과도 같았던 Short Causal Convolution의 제거입니다. 처음엔 “이걸 빼도 Retrieval이 된다고?” 싶었는데, QKNorm(BCNorm) 이후 B와 C에 단순 Bias를 주고 새로운 Recurrence를 태우는 것만으로 Convolution과 유사한 효과를 냈다고 합니다. 불필요한 연산 단계를 줄이면서도 성능을 유지한 아주 깔끔한 결정입니다.
벤치마크와 커널 깎는 장인정신
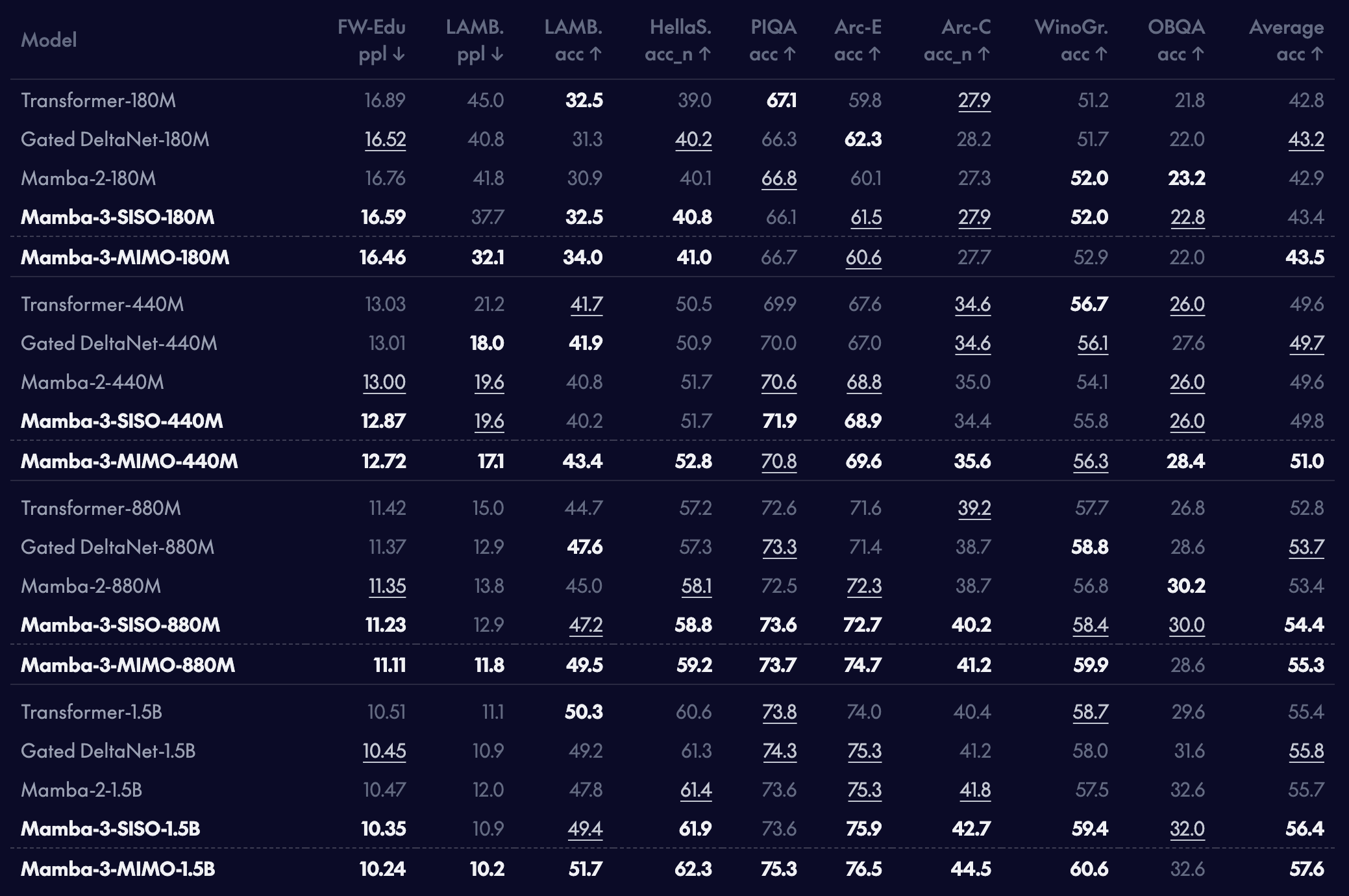
1.5B 파라미터 스케일에서 Mamba-3 SISO 모델은 Llama-3.2-1B는 물론이고 Gated DeltaNet(GDN)보다도 빠른 Prefill 및 Decode Latency를 보여줍니다.
여기서 또 하나 짚고 넘어가야 할 건 커널 최적화입니다. 이 팀은 아키텍처 개발의 표준이 된 Triton은 기본이고, MIMO의 복잡한 메모리 계층 제어를 위해 TileLang을, 극한의 디코딩 성능을 쥐어짜기 위해 CuTe DSL까지 동원했습니다. Python 인터페이스 위에서 CUDA 레벨의 제어권을 행사하며 Hopper GPU의 모든 기능을 영혼까지 끌어다 쓴 셈입니다. 단순히 논문을 위한 코드가 아니라, 당장 프로덕션에 올려도 될 만큼 하드웨어 최적화에 진심이라는 뜻이죠.
Hacker News의 논쟁: Inference vs Prediction
재미있게도 Hacker News 스레드에서는 이 논문의 첫 문단을 두고 작은 키보드 배틀이 벌어졌습니다. 누군가 “Inference 같은 어려운 말 쓰지 말고 예측할 때 빠르다고 쉽게 쓰면 안 되냐”라고 불평했죠. 하지만 다른 엔지니어들이 “이건 기술 블로그고, Inference는 단순한 예측이 아니라 명확히 구분되는 시스템적 병목이다”라며 반박했습니다.
저 역시 후자에 100% 동의합니다. 시니어 엔지니어에게 Inference는 단순한 단어가 아닙니다. 서버 비용, Latency, Throughput이 모두 얽혀 있는 프로덕션의 핵심 과제입니다. 이런 전문 용어를 희석시키는 건 오히려 기술의 핵심 가치를 흐리는 일입니다.
결론: 프로덕션 레디인가?
결론적으로 Mamba-3는 프로덕션 레벨의 고민이 깊게 묻어나는 훌륭한 진화입니다. 단순히 “우리 모델이 벤치마크 1등이에요”가 아니라, “디코딩 때 노는 GPU 자원을 어떻게 알뜰하게 써먹을까”를 치열하게 고민한 결과물입니다.
하지만 선형 모델의 태생적 한계인 Retrieval 성능 부족은 여전히 존재합니다. Transformer의 KV 캐시처럼 과거의 모든 정보를 완벽하게 들여다보는 건 불가능하니까요. 결국 미래는 Mamba-3의 효율적인 Linear Layer와 Transformer의 Self-Attention이 결합된 Hybrid Architecture 가 지배할 것이라 확신합니다. 당장 모든 Transformer를 대체하긴 어렵겠지만, 하이브리드 모델이 나온다면 무조건 테스트해 볼 가치가 있습니다.
References
- Original Article: https://www.together.ai/blog/mamba-3
- Hacker News Thread: https://news.ycombinator.com/item?id=47419391