강화학습과 디퓨전 모델을 관통하는 1950년대 수학: HJB 방정식과 연속 시간 제어
15년 넘게 엔지니어로 구르다 보면, 완전히 새로운 마법처럼 보이던 기술이 사실은 수십 년 전의 수학적 뼈대 위에 세워져 있다는 사실을 깨닫고 소름이 돋을 때가 있습니다. 최근 Generative AI 씬을 휩쓸고 있는 Diffusion Models 와 로보틱스/알고리즘 트레이딩의 핵심인 Reinforcement Learning(RL) 이 정확히 그렇습니다.
솔직히 말해서, 최근 쏟아지는 PyTorch 기반의 논문들을 읽다 보면 추상화된 API 레이어에 갇혀 근본적인 원리를 놓치기 쉽습니다. 하지만 최근 Daniil’s blog에 올라온 연속 시간 RL과 HJB 방정식에 대한 글을 읽고, 이 두 가지 이질적인 도메인이 Hamilton-Jacobi-Bellman (HJB) 방정식 이라는 하나의 아름다운 수학적 구조로 귀결된다는 것을 다시금 상기하게 되었습니다.
오늘은 프레임워크 사용법을 넘어, 수학과 물리학이 어떻게 현대 ML의 근간을 이루는지, 그리고 엔지니어로서 우리가 이 ‘연속성(Continuous)‘을 디지털 컴퓨터(Discrete)로 가져올 때 직면하는 현실적인 문제들에 대해 깊게 파보겠습니다.
1. Bellman 방정식, 이산에서 연속으로
우리에게 익숙한 RL의 Bellman 방정식은 보통 이산 시간(Discrete time)을 다룹니다. 상태 $X_n$에서 행동 $a_n$을 취하고, 다음 스텝으로 넘어가는 식이죠. 하지만 현실 세계의 물리 법칙이나 금융 시장의 가격 변동은 틱(Tick) 단위로 끊어지지 않습니다.
시간 간격 $h$를 $0$으로 수렴시키면, 이산적인 MDP(Markov Decision Process)는 연속적인 확률 미분 방정식(SDE)으로 변모합니다. 이때 Value function $V(x)$가 만족해야 하는 조건이 바로 HJB 방정식 입니다.
$$ \rho V(x)=\max_{a\in \mathcal{A}}\Big{ r(x,a)+\mathcal{L}^a V(x)\Big} $$
여기서 $\mathcal{L}^a$는 Infinitesimal generator로, Drift(방향성)와 Diffusion(노이즈, 불확실성)을 모두 포함하는 연산자입니다. 흥미로운 점은 이 구조가 1840년대 고전 역학에서 파생된 Hamilton-Jacobi 방정식과 완벽하게 동일하다는 것입니다. 입자의 궤적을 최적화하는 물리 법칙이, 에이전트의 보상을 극대화하는 RL의 법칙과 일치한다는 뜻입니다.
2. 뉴럴 네트워크로 미분 방정식 풀기: Continuous-Time RL
엔지니어 관점에서 가장 흥미로운 부분은 이 복잡한 편미분 방정식(PDE)을 어떻게 코드로 구현하느냐입니다. 전통적인 수치해석에서는 그리드(Grid)를 나누고 유한차분법(FDM)을 썼겠지만, 고차원 상태 공간에서는 차원의 저주(Curse of Dimensionality)에 빠집니다.
현대 ML에서는 이를 Policy Iteration 과 Autograd 를 활용해 우회합니다. Value function $V_\theta$와 Policy $\alpha_\phi$를 MLP로 근사하는 것이죠.
아래는 PyTorch의 autograd를 이용해 연속 시간의 Generator $\mathcal{L}^a V(x)$를 계산하는 핵심 코드입니다.
def compute_generator(V_net, x, f_xa, Sigma_xa):
"""L^a V(x) = ∇V · f + ½ Tr(ΣΣᵀ ∇²V)."""
V = V_net(x) # (batch, 1)
grad_V = autograd.grad(V.sum(), x, create_graph=True)[0] # (batch, d)
drift = (grad_V * f_xa).sum(-1, keepdim=True) # ∇V · f
d = x.shape[1]
# Hessian 계산을 위해 각 차원별로 다시 gradient를 구함
H = torch.stack([autograd.grad(grad_V[:,i].sum(), x,
create_graph=True)[0] for i in range(d)], dim=1)
A = Sigma_xa @ Sigma_xa.transpose(-1,-2) # ΣΣᵀ
diff = 0.5 * (A * H).sum(dim=(-2,-1)).unsqueeze(-1) # ½Tr(AH)
return drift + diff이 코드를 처음 봤을 때 꽤나 인상적이었습니다. $\nabla V$와 $\nabla^2 V$(Hessian)를 해석적으로 푸는 대신, 딥러닝 프레임워크의 자동 미분 그래프를 그대로 태워서 PDE의 항들을 구성합니다. LQR(Linear-Quadratic Regulator)이나 Merton Portfolio 같은 고전적인 최적 제어 문제의 해석적 해(Analytical solution)와 이 뉴럴 네트워크의 결과가 완벽히 일치한다는 것은 아래 그래프가 증명합니다.
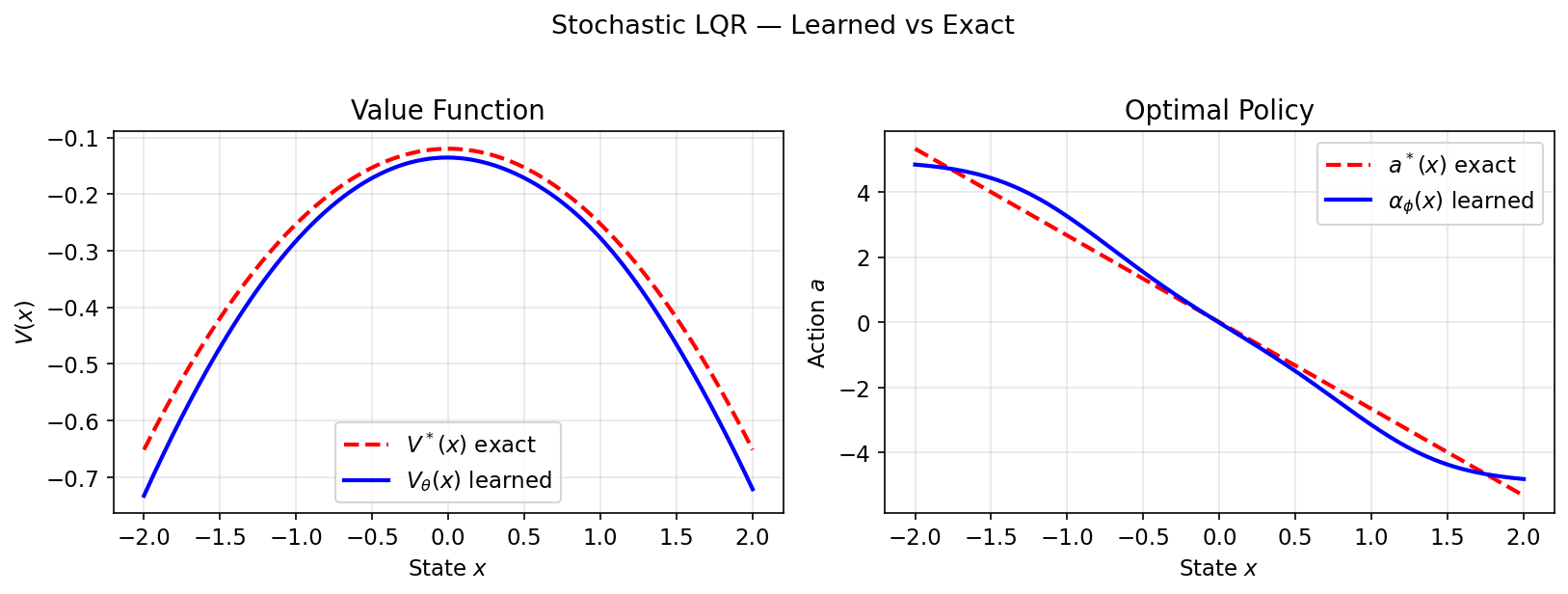
3. Diffusion Models: 시간을 거슬러 올라가는 최적 제어
이 글의 백미는 HJB 방정식을 Diffusion Models 에 연결하는 3장입니다.
Diffusion 모델의 학습 과정을 ‘노이즈를 추가하고 다시 빼는 과정’ 정도로만 이해하고 있었다면, 이 관점은 완전히 새로운 통찰을 줍니다. 노이즈가 낀 데이터 분포 $p_T$에서 원본 데이터 분포 $p_{\text{data}}$로 역재생(Reverse-time)하는 과정을 Stochastic Optimal Control 문제로 정의할 수 있습니다.
이때 Value function을 역시간 마지널의 음의 로그 밀도로 정의합니다. $$ V(x, t) := -\log p_{T-t}(x) $$
이 정의를 HJB 방정식에 대입하고 최적 제어 법칙 $u^(x, t)$를 구하면 놀라운 결과가 나옵니다. $$ u^(x, t) = \sigma(T-t)^\top \nabla_x \log p_{T-t}(x) $$
결국 최적의 제어 정책(Optimal policy)이 우리가 Diffusion 모델에서 학습하는 Score function (데이터 밀도의 그래디언트) 과 정확히 일치하게 됩니다. 즉, 미드저니(Midjourney)나 스테이블 디퓨전(Stable Diffusion)이 이미지를 생성하는 과정은, 본질적으로 1950년대 Bellman이 고안한 최적 제어 문제를 풀고 있는 것과 같습니다.
4. Hacker News의 반응: 수학적 추상화 vs 엔지니어링의 현실
Hacker News 스레드(https://news.ycombinator.com/item?id=47571495)에서는 이 글을 두고 매우 현실적이고 치열한 토론이 벌어졌습니다.
가장 눈에 띄는 반응은 두 가지였습니다.
- 수학에 압도당하는 엔지니어들: 한 유저는 “나는 박사 출신 수학자들에게 완전히 압도당한 느낌이다. 소프트웨어 엔지니어로서의 내 미래가 걱정된다”고 토로했습니다. 하지만 이에 대한 반론도 만만치 않았습니다. 순수 수학이 ML 연구(특히 Diffusion, Geometric DL)에서는 필수적이지만, 대다수의 소프트웨어 엔지니어링은 여전히 시스템 설계와 아키텍처의 영역이라는 것이죠.
- 연속(Continuous) vs 이산(Discrete)의 간극: 제가 가장 공감했던 기술적 논쟁입니다. 수식 위에서는 실수(Real numbers)와 무한한 정밀도가 존재하지만, 컴퓨터는 결국 이산적인 64비트 Float 기계입니다. 한 유저가 지적했듯, “해석학적 방정식이 디지털 알고리즘으로 매핑된다는 것 자체가 결코 자명한 일이 아닙니다.”
단순히 시간 간격 $\Delta t$를 작게 쪼갠다고 해서 안정적인 모델이 나오는 것이 아닙니다. 수치해석학(Numerical Analysis)에서 말하는 Condition number, CFL 조건, Discretization error 등을 제어하지 못하면 모델은 발산해버립니다. 우리가 PyTorch나 JAX 같은 프레임워크를 편하게 쓸 수 있는 이유는, 그 밑단에서 누군가가 이 수치적 불안정성을 C++/CUDA 레벨에서 피땀 흘려 잡아놓았기 때문입니다.
5. 총평 (Verdict)
이런 류의 깊은 수학적 배경을 다루는 글은 당장 내일 아침의 스프린트 티켓을 쳐내는 데는 아무런 도움이 되지 않을지도 모릅니다. 하지만 시니어, 혹은 프린시펄 엔지니어로 성장한다는 것은 결국 ‘현상의 기저에 있는 원리(First Principles)’ 를 이해하는 과정입니다.
프레임워크의 API는 매년 바뀝니다. 하지만 Bellman 방정식과 HJB 방정식, 그리고 이를 통한 최적화의 원리는 70년이 지난 지금도 최첨단 AI의 심장부에서 뛰고 있습니다.
만약 당신이 차세대 생성형 AI 모델의 구조를 설계하거나, 자율주행/로보틱스의 연속 제어 시스템을 최적화해야 하는 포지션에 있다면, 이 논문과 수학적 뼈대는 반드시 소화해야 할 필수 교양입니다.
References:
- 원문 블로그: Hamilton-Jacobi-Bellman Equation: Reinforcement Learning and Diffusion Models
- Hacker News 토론: HN Thread (47571495)